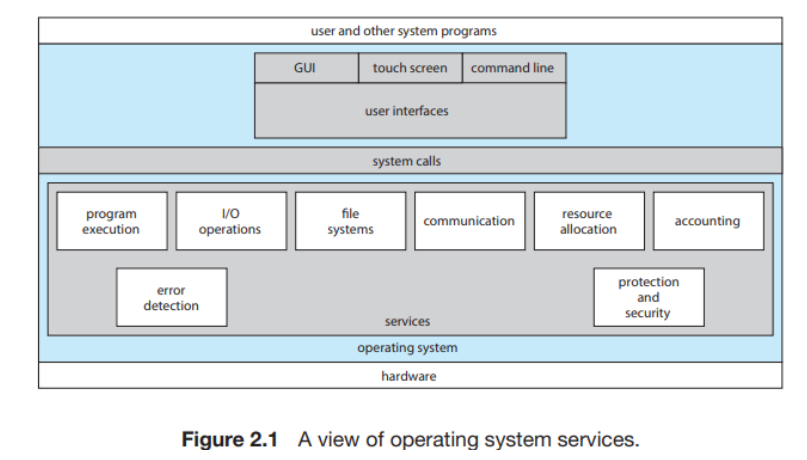
본 포스팅은 공룡책으로 불리는 Abraham Silberschatz, Peter B. Galvin, Greg Gagne의 『Operating System Concept 10th』 기반으로 정리한 글입니다.
Process Concept
프로세스란?
- 실행 중인 프로그램
- OS의 작업 단위
- 하나의 프로세스가 실행되기 위해 자원 필요
- CPU, memory, files, I/O devices
프로세스 상태 정보는 (1) program counter와 (2) contents of the processor's register로 구성
프로세스 레이아웃

- Text section ⇒ 명령어 실행 코드
- Data section ⇒ 전역 변수들
- Heap section ⇒ 함수 호출시 dynamic하게 저장되는 메모리
- Stack section ⇒ 함수 파라미터, 리턴되는 주소나 지역 변수를 저장하는 일시적 데이터 저장
- Text와 Data 부분은 고정
- Stack와 Heap 부분은 동적
- Stack은 grow down
- Heap은 grow up
⇒ 겹치지 않게 OS가 조절

Program and Process
- program : 디스크에 저장된 명령어 리스트를 포함하는 파일 (executable file)
- process : 다음 실행할 명령어를 나타내는 program counter와 관련 자원 집합을 가짐
- 두 process가 동일 program과 관련되더라도 두 개의 독립된 실행 순서로 간주됨 ⇒ 이 경우 Text section은 동일하고 나머지는 다름
Process State

- New : 프로세스가 막 생성된 상태
- Running : CPU가 프로세스를 점유하여 프로세스를 로딩하는 상태
- Waiting : 다른 프로세스가 CPU를 점유할 때
- Ready : I/O 대기하고 있다가 점유할 준비, 대기중
- Terminated : 프로세스 실행 끝남
processor core에서 실행될 수 있는 process는 오직 한 번에 한 개뿐이지만, ready나 waiting 상태는 많은 process들이 존재할 수 있다.
Process Control Block (PCB)

PCB는 구조체 내 프로세스가 가져야하는 모든 정보들을 저장하는 저장소이다.
프로세스마다 각각 PCB를 가지며 이는 doubly linked list로 구현된다.
각 프로세스가 가져야하는 모든 정보들을 저장한다.
- Process state : new/running/ready/waiting/halted 등
- Program counter : 다음 명령어의 주소
- CPU registers : interrupt 발생 시 PC와 함께 상태 정보 저장하여 reschedule 후 계속 실행됨
- Memory-management information
- Accounting information
- I/O status information
Threads
Single thread of execution
- Process는 single thread를 실행하는 program
- 현대 OS 프로세스
- single thread 제어는 한번에 하나의 task만 실행됨 (ex. 문자 입력과 철자 검사를 동시에 X)
Multiple Thread
- Process가 여러 실행 thread만 가지고 한 번에 하나 이상의 tasks를 실행함
- Multi core system인 경우 여러 thread가 병렬로 실행 가능
- Thread 지원 system에서 PCB가 각 thread에 대한 정보를 포함하도록 확장
Process Scheduling
Multiprogramming
항상 process들이 실행되도록 하여 CPU 이용률을 최대화한다.
multiprogramming의 목적
- 동시에 여러 프로세스 실행
- CPU 사용률 증가
- Time sharing으로 프로세스 내 CPU core를 스위치하여 각 프로그램이 동시에 돌고 있는 것처럼 보이도록 함
Time sharing
Process 사이에서 CPU core를 자주 switch하여 user와 program이 상호작용한다.
→ core에서 프로그램을 실행하기 위해 process scheduler가 실행 가능한 process를 하나 고른다.
Single CPU core를 가진 system에서는 한 번에 한 process만 실행 가능하지만, multicore system에서는 multiple processes들이 동시에 실행될 수 있다.
이때 core의 수보다 process의 수가 더 많은 경우 process들이 wait해야 한다.
- multiprogramming과 time sharing의 균형을 위해 적절히 스케줄링 해야한다.
- 시간 소비에 따라 I/O bound or CPU bound process로 구분된다.
Degree of multiprogramming
현재 메모리 내 process 수
Scheduling Queues

- Process가 system에 진입하여 Ready queue에 삽입되어 대기한다.
- IO가 있으면 wait queue로 삽입된다.
- Ready Queue / Wait Queue는 linked list 형태로 저장된다.
- queue의 head는 첫 PCB 포인터를 가지며, 각 PCB는 다음 PCB에 대한 포인터를 가진다.
Queueing Diagram
종료 시점에 queue에서 제거되고 PCB와 자원이 해제된다.

CPU Scheduling
process는 ready queue와 wait queue 사이를 이주한다.
CPU scheduler의 역할
- ready queue에서 하나의 process를 선택하고 CPU core를 할당한다.
- I/O bound process → 잠깐 실행 후 I/O 대기
- CPU bound process → 오랜 기간동안 CPU core가 필요해도 장기간 할당될 가능성은 없음 (CPU를 뺏어서 다른 process에게 스케줄함)
Swapping - 메모리 과부하 상태일 때 process 제거
- memory에서 process를 제거하여 다중화 정도를 낮추는 것
- 나중에 다시 memory로 적재되어 중단된 위치에서 계속 실행됨
- swapped out = 메모리 → 디스크
- swapped in = 디스크 → 메모리
- 메모리가 초과 사용되어 해제되어야할 때만 필요
Context Switch (문맥 교환)
- CPU가 다른 프로세스와 CPU core를 교환하는 것
- Context : PCB 내 프로세스가 사용되고 있는 상태, PCB로 보면 됨
- interrupt 발생
- 실행 중인 프로세스의 현재 context 저장 (PC, 어디까지 저장했는지)
- OS는 현재 task로부터 CPU core를 뺏아 kernel 루틴을 실행하게 함
- 다른 프로세스 로딩시 저장한 context를 restore

- 다른 process에게로 CPU core를 switching하는 것
- PCB에 old process의 문맥을 저장하여 실행될 new process의 saved 문맥을 load
Operations on Processes
프로세스는 동시에 수행되고 동적으로 생성/삭제된다.
프로세스는 새로운 프로세스를 생성할 수 있다. → 부모/자식 프로세스 by fork()
Process Creation
- 실행 중에 process는 새로운 process를 생성한다.
- 생성한 process = 부모 process
- 생성된 process = 자식 process
- 부모/자식 process는 병렬적으로 실행
- 부모는 자식이 종료될 때까지 기다림
- 자식이 부모의 복제본이면 부모와 동일한 프로그램과 데이터를 가짐 [fork() system call]
- 자식 process가 자신에게 load되는 새로운 프로그램을 가짐
Process identifier (pid)
- pid로 process를 식별
- kernel 내에서 다양한 process의 속성에 접근하기 위한 index로 사용
command
- ps -el : 현재 실행 중인 process들의 list를 보여줌
- pstree : tree로 보여줌
systemd process (pid=1)
- root parent process
- 모든 user process들의 부모이며 부트 시 생성되는 첫 user process
- 부팅되면 systemd가 추가적인 서비스를 제공하는 process를 생성함
Child process가 자원을 필요로 할 때
- 자식 process가 OS로부터 직접 자원을 할당받거나 부모 process 자원의 부분집합으로 제한
- 부모는 자식들 간 자원을 분할하여 사용하거나 자식들과 자원 공유
→ 한 프로세스가 너무 많은 자식을 생성하여 시스템을 과부하시키는 것을 막음
Child process에 필요한 data 전달
- OS가 자식 process에게 자원을 전달
- 부모 process가 자식 process에게 초기화 data 전달
자식 process
- 부모로부터 자원뿐만 아니라 특권, 스케줄링 속성을 물려받음
- exelip()를 이용해 자신의 주소 공간을 ls 명령어로 덮어씀
부모 process

- wait() system call을 이용하여 자식 process가 끝날 때까지 기다림
- 자식 process 종료 시, 부모는 wait() 호출로부터 재개
UNIX OS에서의 process 생성 과정
fork() system call : 새로운 process 생성하는 시스템 콜
- 새로운 process는 original 주소 공간의 복사본으로 구성됨
- 부모와 자식이 쉽게 통신하게 함
- pid = for() : 리턴 = (1) 0 (자식) (2) child의 pid (부모)
After a fork() system call
- fork() 후, 한 process가 exec() system call하여 메모리 공간을 새 프로그램으로 교체
- binary file을 memory로 적재하고 실행함
- 적재 : 자신을 포함한 프로그램의 메모리 이미지를 파괴(덮어쓰기)
- 자식을 더 생성하거나 자식이 실행되는 동안 할 일이 없으면 자식이 종료될 때까지 ready queue에서 자신을 제거하기 위해 wait() system call을 함
Process Termination
return(final Statement)로 종료를 명시하거나 exit()로 중도 out처리한다.
OS 입장에서는 메모리 및 자원 해제, 회수한다.
스스로 종료
- 마지막 문장을 실행하여 종료하고 exit() system call로 OS에 자신을 삭제 요청함
- wait() system call을 통해 대기 중인 부모 process에 상태값이 반환됨
- process의 자원들은 OS에 의해 할당이 해제되고 회수됨
다른(부모) process에 의한 종료
- system call로 다른 process를 종료시킴 (TerminateProcess() in Window)
- 종료시키는 system call은 부모 process로부터 호출됨
- process 종료를 위해서 부모는 자식의 pid를 알아야함
- process 생성 시 부모에게 pid 전달
- 이유
- 자식이 할당된 자원을 초과 사용한 경우
- 자식에게 할당된 task가 더 이상 필요하지 않은 경우 task 종료
- 부모가 exit시 자식이 계속 실행되는 것을 OS가 허용하지 않은 경우
Cascading termination
- 부모가 종료되면 자식이 존재할 수 없음 → 모든 자식이 종료되어야 함
- 자식이 종료될 때 pid가 return되어 부모는 어느 자식이 종료됐는지 식별
- pid = wait(%status) // exit(1) → 1인 status로 종료
사용자에 의한 종료
Process Table
PCB의 array는 현재 존재하는 모든 process의 PCB이다.
→ process의 exit status가 process table에 저장되므로 process table의 항목은 부모가 wait()를 호출할 때까지 남아있어야 한다.
Zombie Process → 정상 종료 가능
- 종료되었거나 부모가 아직 wait()를 호출하지 않은 process
- 자식 할 일 하게 냅워서 자식은 좀비처럼 계속 남아있음
- 부모가 wait()를 호출하면 좀비의 process pid와 process table의 항목이 해제됨
Orphan Process → 정상 종료 불가능
- 부모가 wait()를 호출하지 않고 종료한 경우 PCB에 정보가 계속 남음
- 이를 System 선에서 정리해야하는데, init process를 orphan process의 새로운 부모로 지정하여 해결
- int이 주기적으로 wait()를 호출하여 orphan process의 exit status를 수집하고 orphan process의 id와 process table 항목을 해제함
Interprocess Communication (IPC)
Process 간 협력 이유
- Information sharing
- Computation speed up
- Modularity
IPC Model
- shared-memory model → 공유 메모리 주고 받음
- 공유 메모리 영역을 만들 때만 system call이 일어나므로 빠름
- 공유 메모리가 만들어지면 모든 접근이 일상적인 메모리 접근으로 취급되고 커널 도움 필요 없음
- process들은 동시에 동일 위치에 쓰지 않도록 책임져야 함
- message-passing model → 메세지 주고 받음
- 작은 data 교환시 유용
- 분산 system 환경에서 구현 쉬움
- 느림

IPC in Shared-Memory Systems
- 공유 메모리 영역은 공유 메모리 segment를 생성하는 process의 주소 공간에 위치
- 공유 메모리 segment를 사용해 통신하기 원하는 process들은 자신의 주소 공간에 추가
- process들은 동시에 동일 위치에 쓰지 않도록 책임져야함
A solution using shared-memory
producer(정보 생산)와 consumer(정보 소비)는 동시에 실행되고, CPU를 잘 나눠서 점유한다.
- Complier → assembly code 생산, assembler → assembly code 소비
- client-server 패러다임
- 동시에 실행하기 위해 producer는 buffer를 채우고, consumer는 이를 받아 사용함
- producer와 consumer는 동기화되어야 함 → 생산되지 않은 정보를 소비하지 않음
Buffer
Buffer가 가득차면 Producer는 wait, 아직 모자라면 Consumer는 wait 상태를 유지한다.
- unbounded buffer : consumer는 item 대기 가능, producer는 계속 생성 가능
- bounded buffer : consumer는 empty일 때 대기, producer는 full일 때 대기 ⇒ 원형 배열로 구현
IPC in Message-Passing Systems
Shared-Memory system의 복잡한 내용들을 OS가 처리하게끔 한다! (By cooperating process 수단)
- 네트워크로 연결된 다른 컴퓨터들의 process간 통신
- send(message) receive(message)
- message의 길이는 고정이거나 가변이고, 통신을 원하면 message를 주고 받아야함
- fixed-sized message : 시스템 수준 구현은 단순하나 task 프로그래밍이 어려움
- variable-sized message : 시스템 수준 구현은 복잡하나 task 프로그래밍이 쉬움
- Naming → 통신을 원하는 process들은 서로 통신 상대를 지정해야
Direct communication (직접 연결 통신)
recipient/sender process의 이름을 명시한다.
- send(P, message) : process P에게 메세지 전달
- receive(Q, message) : process Q로부터 메세지 받음
- P와 Q가 직접적으로 연결됨
- communication link는 자동으로 생성되고, 하나의 링크만 성립됨
단점
- process 정의에서 modularity가 제한됨
- process id의 변경은 모든 다른 process 정의를 검사해서 변경해야 함
- id가 직접적으로 명시되는 hard-coding 기법
- Symmetry in addressing
- 통신하려면 둘 다 상대의 이름을 지정
- Asymmetry in addressing
- sender만 recipient를 naming
- send(P, message)
- receive(id, message) : any process로부터 받음 (id는 통신이 일어난 process의 이름)
Indirect communication (간접 연결 통신) - mailbox
- mailbox는 process들이 메세지를 저장(send)하고 제거(receive)하는 객체
- 두 process가 공유 mailbox를 가질 때만 통신 가능
- 여러 mailbox를 통해 다른 process들과 통신
- send(A, message), receive(A, message) : mail box A를 통해서 통신
둘 이상의 process가 같은 mailbox를 공유하는 경우
- link가 최대 두 process만 연관되도록 제한
- 최대 한 번에 한 process만 receive()
- 어떤 process가 메세지를 receive할 지 선택 (round robin)
mailbox 소유
- process 소유
- 소유자(수신자)와 사용자(송신자)로 구분
- 각 mailbox마다 고유한 owner가 있음
- mailbox를 갖는 process가 종료되면 mailbox도 사라짐
- 사라진 mailbox에 메세지를 보내는 process는 mailbox가 없음을 통보받음
- OS 소유
- 독립적으로 존재하여 특정 process에 속하지 않음
- process가 mailbox를 생성/삭제하는 기능을 OS가 제공
- mailbox를 생성하는 process가 owner
- mailbox에 대한 권한은 system call로 다른 process에 전달 가능
Synchronization 동기화
- process 간 통신은 send() / receive() 호출로 발생
- blocking (synchronous) Send : 수신될 때까지 send 대기 → 수신 후 송신
- 메세지가 받아들여질 때까지 sender는 블락됨
- blocking (synchronous) Receive : 메세지가 avail할 때까지 receive 대기 → 송신 후 수신
- 메세지 available할 때까지 receiver는 블락됨
- nonblocking (asynchronous) Send, Receive
- sender가 메세지 보내고 할 일 계속함
- receiver가 유효하거나 빈 메세지를 되찾아옴 (Retrieve)
⇒ send와 receive의 종류에 따라 4가지 조합 가능
Buffering
- 메세지는 temporary queue에 보관
Queue 세 가지 구현 방법
- Zero capacity : 보관 X
- Bounded capacity : N개 메세지 보관
- Unbounded capacity : 무한개 보관
'CS > 운영체제' 카테고리의 다른 글
| [공룡책🦖] ch6 Synchronization Tools (0) | 2023.07.20 |
|---|---|
| [공룡책🦖] CPU Scheduling (1) | 2023.07.19 |
| [공룡책🦖] 쓰레드 & 동시성 Threads & Concurrency (0) | 2023.07.14 |
| [공룡책🦖] 운영체제 구조 (0) | 2023.07.02 |
| [공룡책🦖] 운영체제란? (0) | 2023.06.27 |