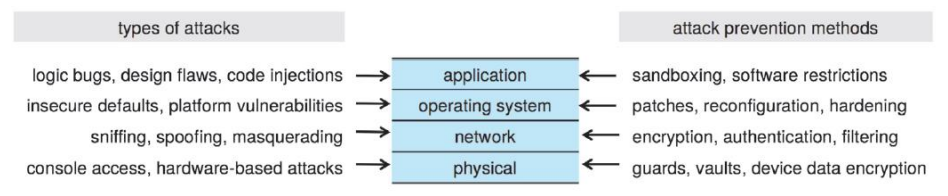
GoF 디자인 패턴 중 하나로, 전략 패턴은 전략을 쉽게 바꿀 수 있도록 하는 디자인 패턴이다.
여기에서 전략이란 어떤 목적을 달성하기 위해 일을 수행하는 방식, 비즈니스 규칙, 문제를 해결하는 알고리즘 등으로 이해할 수 있다.
프로그램에서 알고리즘의 집합을 정의하고 각각을 캡슐화하여 상호 교환 가능하도록 만든다.
알고리즘을 사용하는 클라이언트와 독립적으로 알고리즘을 변경하거나 확장할 수 있으며, 코드의 재사용성과 유연성을 높일 수 있다.
전략 패턴 예제
어떤 소재를 가지고 전략 패턴 알고리즘을 작성해볼까 고민하다가 GPT가 게임 캐릭터와 공격 방식을 추천해줬다.
이를 바탕으로 게임 캐릭터, 그리고 캐릭터의 공격방식을 바탕으로 각각 클래스를 작성하였다!
공격 방식
// 전략 인터페이스: 공격 방식을 정의하는 인터페이스
interface AttackStrategy {
void attack();
}
비어있는 attack() 함수만 정의되어있는 공격 전략 인터페이스다.
공격 방식 클래스들
class FighterAttack implements AttackStrategy {
@Override
public void attack() {
System.out.println("검으로 공격!");
}
}
class ArcherAttack implements AttackStrategy {
@Override
public void attack() {
System.out.println("활로 원거리 공격!");
}
}
class MageAttack implements AttackStrategy {
@Override
public void attack() {
System.out.println("마법으로 공격!");
}
}
AttackStrategy 인터페이스를 구현한 구체적인 공격방식 클래스이다.
클래스 별로 attack()을 구체적으로 구현하였다!
게임 캐릭터 클래스
class GameCharacter {
private AttackStrategy attackStrategy;
public void setAttackStrategy(AttackStrategy attackStrategy) {
this.attackStrategy = attackStrategy;
}
public void attack() {
attackStrategy.attack();
}
}
게임 캐릭터 클래스이다.
AttackStrategy 인터페이스를 활용하여 공격전략을 바꿀 수 있는 setAttackStrategy와 AttackStrategy의 공격 방식을 출력하는 attack()이 있다.
Main문
public class StrategyPatternExample {
public static void main(String[] args) {
// 캐릭터 생성
GameCharacter character = new GameCharacter();
// 초기 공격 방식 설정
character.setAttackStrategy(new FighterAttack());
// 캐릭터가 검으로 공격
character.attack();
// 캐릭터가 활로 공격으로 전환
character.setAttackStrategy(new ArcherAttack());
character.attack();
// 캐릭터가 마법으로 공격으로 전환
character.setAttackStrategy(new MageAttack());
character.attack();
}
}
캐릭터를 생성하여 공격 방식을 설정하고 공격한다.
다른 공격 방식으로 전환한 뒤 공격을 취하는 구조이다.
게임 캐릭터가 원하는 공격 방식을 취하고 공격을 할 때마다 다르게 출력됨을 확인할 수 있다.
이렇게 전략 패턴을 사용하면 새로운 공격 방식을 추가하거나 기존 방식을 변경하는 작업이 캐릭터 클래스를 수정하지 않고도 가능하다.
스프링에서 UserDao를 통해 Connection객체를 변경할 수 있는 예시에도 전략패턴이 사용되는데, 추후에 학습 후 직접 작성해봐야겠다!
본 포스팅은 공룡책으로 불리는Abraham Silberschatz, Peter B. Galvin, Greg Gagne의 『Operating System Concept 10th』기반으로 정리한 글입니다.
System Model
Multiprogramming 환경에서는 여러 스레드들이 유한한 자원을 두고 경쟁하며 스레드에 분배한다.
스레드가 다른 대기 중인 스레드가 점유 중인 자원을 요청해 waiting state인 경우가 계속 발생할 수 있다.
이처럼 데드락은 모든 프로세스들이 다른 프로세스의 이벤트를 대기하고 있을 때를 말한다.
시스템 모델에서 한정된 리소스로 구성된 시스템을 여러 스레드로 공유해야함
리소스 타입은 여러 개의 동일한 인스턴스 타입으로 구성 : e.g., CPU cycles, files, and I/O devices(such as printers, drive, etc.)
스레드(혹은 프로세스)가 어떤 리소스의 한 인스턴스를 요청시동일 리소스의 인스턴스를 할당하여 요청을 충족
리소스의 타입이 중요하고, 안의 인스턴스의 개수는 중요하지 않음
스레드가 리소스를실행할 때 과정 ⇒ Request(요청) → Use(사용) → Release(해방)
Deadlock in Multithreaed Applications
서로 hold 중인 lock을 요청하는 상황 (deadlock)
스레드 실행 순서에 따라 데드락이 안 일어 날 수 있다.
스레드2가 lock을 획득하기 전, 스레드1이 mutex1, mutex2에 대한 lock을 획득하고 해제한다.
그러나 특정 스케줄링 상황에서만 발생하는 데드락에 대한 식별과 검사는 어렵다.
Deadlock Characterization
데드락을 발생시키기 위해 특정 짓는 네 가지 조건이 있다.
1. Mutal Exclusion (상호 배제)
어떤 리소스에 접근할 때 순간적으로 하나의 프로세스만 접근할 수 있음
적어도 하나의 리소스가 non-sharable mode
2. Hold and Wait (점유 후 대기)
프로세스는 적어도 하나의 리소스를 점유하고 있고 다른 스레드의 추가 리소스 획득을 대기하고 있음
프로세스가 리소스를 점유하고 있지 않으면, 애초에 데드락이 일어나지 않음.
3. No preemption (선점 불가)
리소스는 선점될 수 없음
선점이 되어버리면 프로세스가 실행을 종료하니 데드락이 일어나지 않음
4. Circular Wait (순환 대기)
프로세스가 순환적으로 서로를 기다리고 있음
스레드 circular RAP
T0 → T1 → T2 → ... → Tn → T0
Resource-Allocation Graph(RAP)
데드락을 정확하게 묘사한 단방향 그래프
각 정점을V라고 칭하며V에는 두 가지 타입 존재
T: 스레드 집합
R: 리소스 집합
각 간선은E라고 칭하며 두 가지 타입 존재
Ti → Ri (Request edge) Ti가 Ri를 요청
Ri → Ti (assignment edge) Rj가 Ti에 할당됨
왼쪽 그림 : 순환 대기로데드락이 일어나지 않은 상황 (만약 그래프 내 사이클이 있다면 데드락 가능성 O)
인스턴스가 하나인 경우 → 사이클은 데드락 의미
인스턴스가 여러 개인 경우 → 사이클이 데드락 의미 X
오른쪽 그림 :T3가 R2에게 리소스를 요청하면서 데드락 발생
T1, T2, T3간 데드락 발생
T1과 T3 사이 사이클이 존재하지만 R2의 인스턴스는 2개 → T4가 작업을 완료하고 리소스를 놓아주면 T3가 R2에 접근할 수 있으므로 데드락 발생하지 않음
RAP에서 사이클을 그리지 않으면 데드락은 절대 발생하지 않는다.
사이클이 발생한다고 해서 데드락이 무조건 발생하는 것은 아니다.
Methods for Handling Deadlocks
1. 문제 발생 무시 (발생하지 않을 것이라고 가정)
2. 데드락을 방지/회피하기 위한 프로토콜 사용
프로토콜을 이용하여 어떤 상황에서도 데드락에 빠지지 않게 설정
Deadlock prevention
Deadlock avoidance
3. 시스템이 데드락 상황에 빠진 것을 확인했을 때 회복
Deadlock detection
Deadlock recovery
Deadlock Prevention
데드락을 완전히 방지하는 방법
데드락 발생의네 가지 조건 중 하나를 완전히 해결해 데드락을 예방하는 방법
1. Mutual Exclusion
리소스가 공유할 수 있도록 함
특정 자원은 근본적으로 공유가 불가능하므로 현실적으로 어려움
2. Hold and Wait
프로세스가 리소스를 점유하고 있지 못하게 하는 방법
Hold와 Wait을 동시에 하지 않도록 함
프로세스가 리소스를 요청할 때, 가지고 있는 리소스를 모두 내려놓고 리소스를 요청하고, 이후 획득시 가지고 있던 리소스 다시 요청
Resource utilization 저하
Starvation 발생 가능
3. No preemption
다른 프로세스가 리소스를 점유하고 있을 때 해당 리소스 빼앗을 수 있음
선점당한 프로세스는 어떤 작업을 하든 waiting 상태로 전환
이전 리소스와 새 리소스를 되찾아야 이전 프로세스 실행 가능
4. Circular Wait
4가지 방법 중 가장 실용적
리소스에 순서를 부여하여 오름차순으로 리소스를 할당하는 방법
우선순위를 부여하는 것과 마찬가지로 기아 상태가 발생할 가능성 존재
Deadlock Avoidance
데드락 방지를 사용하면 디바이스 사용률이 낮아지고, 시스템의 처리량이 감소할 위험이 높아지며멀티 스레딩으로 얻은 장점이 사라진다.
이를 피하기 위해데드락 회피 방법을 사용한다.
프로세스들에 배분할 수 있는 자원의 양을 고려해 데드락이 발생하지 않을 정도로 자원을 배분하는 방법이다.
프로세스의 리소스 요청을 받을 때시스템은 발생 가능한 데드락이 있는지 먼저 확인
데드락이 발생하지 않으면 리소스 요청 허용O, 데드락이 발생하면 요청 허용X
얼만큼의 리소스 양이 필요하며 어느 타입의 리소스 요구되는지? ⇒ 필요한 정보의 양과 유형에 따라 다양한 회피 알고리즘 존재
Safe State
Safe, unsafe, and deadlocked state spaces
시스템이 특정 순서대로 스레드에 리소스를 할당하고 데드락도 발생하지 않는 상태
해당 순서 :안전 배열(safe sequence)
안전 배열이 있으면 시스템은 safe state(not deadlock state)
데드락을 회피하기 위해서는 알고리즘을 이용하여안전하지 않은 상태에서 안전한 상태로 이동할 수 없게 설정
안전한 상태의 스레드는 계속해서 안전한 상태로 머물러야 함
Resource-Allocation-Graph Algorithm
각 리소스 유형의 인스턴스가 한 개만 존재할 때
새로운 간선을 그릴 때실선이 아닌 점선 → 클레임 엣지(claim edge) (스레드가 나중에 리소스를 요청할 수 있음)
점선을 이용하여 선을 그렸을 때사이클이 일어나지 않는지 확인 →사이클이 그려지지 않으면 안전 상태로 판단 →사이클이 그려지면 안전하지 않은 상태로 판단
사이클이 발견되면 스레드는 요청이 충족될 때까지 wait
Banker's Algorithm
RAG는 multiple instance에 사용못하기에 은행원 알고리즘 사용
여러 인스턴스가 있을 때 데드락 회피를 위한 방법으로 적합
RAG에 비해 복잡하고 효율이 떨어짐
리소스의 최대 개수를 할당해도 안전한 상태가 유지되는지 확인
안전하지 않은 상태면 다른 스레드가 자원 해제할 때까지 wait
Data structures for Banker's Algorithm
n : 시스템에 있는 스레드의 수
m : 시스템에 있는 리소스의 수
Available : 사용 가능한 리소스의 인스턴스 수
Max : 각 스레드가 요청할 인스턴스의 최대 수
Allocation : 각 스레드에 할당된 리소스의 수
Need : 앞으로 요청할 리소스의 수
Request : 스레드가 요청한 리소스의 수
Safety Algorithm
1. Work, Finish 벡터를 아래와 같이 초기화한다.
Work = Available, Finish[i] = false
2. 아래의 두 조건을 만족하는 인덱스를 찾는다.
Finish[i] == false, Need[i] <= Work
만족하는게 없다면 4번으로 간다.
조건을 만족한다면 아래를 실행한다.
3. Work = Work + Allocation[i]
Finish[i] = true
다시 2번으로 돌아가 끝날 때까지 반복한다.
4. 만약 Finish[i]가 모두 true라면, 안전한 상태라는 의미이다.
Resource - Request Algorithm
1. Request[i] <= Need[i] 이면 2번으로 간다.
반대의 경우 최초 등록한 Max 보다 더 많은 양의 리소스를 요청했다는 것을 의미한다.
2. Request[i] <= Available[i] 이면 3번으로 간다.
반대의 경우 할당 가능한 인스턴스의 양보다 요청 양이 더 많다는 것을 의미한다.
3. 요청을 받아주며 아래의 식을 적용한다.
Allocation[i] = Allocation[i] + Request[i];
Available = Available - Request[i];
Need[i] = Need[i] - Request[i];
4. 이 후 다시 위의 안전 알고리즘을 적용하여 안전한 상태라면 리소스를 완전히 할당한다.
Deadlock Detection
데드락이 일어났는지 확인하기 위한 시스템 상태를 검사하는 알고리즘
데드락을 허용하고 발생하는지 감시하고, 데드락에 빠지면 그 때 복구
Single Instance of Each Resource Type
리소스에 인스턴스가 1개 있는 경우에는 위의RAG를 변형한 wait-for graph 사용
주기적으로 알고리즘을 실행하여사이클이 있는지 확인
그래프에서 리소스를 제외
Several Instances of a Resource Type
은행원 알고리즘을 변형하여 데드락 탐지
1. Work = Available 로 초기화하고, Allocation[i] 가 0이면 Finish[i] 를 true로 설정한다.
2. 아래의 두 조건을 만족하는 스레드를 찾는다.
Finish[i] == false, Request[i] <= Work
마찬가지로 조건에 만족하는 스레드가 없다면 4번으로 간다.
3. 아래의 두 연산을 실행한다.
Work = Work + Allocation[i], Finish[i] == true
4. Finish[i] == false 이면 해당 스레드는 데드락이 발생한 상태임을 의미한다.
본 포스팅은 공룡책으로 불리는Abraham Silberschatz, Peter B. Galvin, Greg Gagne의 『Operating System Concept 10th』기반으로 정리한 글입니다.
Classic Problems of Synchronization
다수 동시성 제어의 고전적 문제
Bounded-Buffer Problem (유한 버퍼 문제)
Readers-Writers Problem (읽기 쓰기 문제)
Dining-Philosophers Problem (철학자들의 저녁식사 문제)
1. Bounded-Buffer Problem
Producer-Consumer 문제
소비자와 생산자가 공유하는 데이터
각각 하나의 항목을 보유할 수 있는 n개의 버퍼와 상호배제를 제공하는 이진 semaphore로 구성된 풀이 있다고 가정
생산자는 소비자를 위해 버퍼를 가득 채워야 함
소비자는 생산자를 위해 버퍼를 비워야 함
생산자 프로세스 코드
while (true) {
/* produce an item in next produced */
wait(empty);
wait(mutex);
/* add next produced to the buffer */
signal(mutex);
signal(full;
}
empty 세마포가 0보다 클 때 (빈 공간이 있을 때)
mutex가 존재할 때 (락을 얻을 수 있을 때)
임계구역에 진입해서 버퍼에 데이터를 입력할 수 있다.
소비자 프로세스 코드
while (true) {
wait(full);
wait(mutex);
/* remove an item from buffer to next consumed */
signal(mutex);
signal(empty);
/* consume the item in next consumed */
}
full 세마포가 0보다 클 때 (버퍼에 데이터가 있을 때)
mutex가 존재할 때 (락을 얻을 수 있을 때)
임계구역에 진입해서 버퍼를 소비할 수 있다.
유한 버퍼 문제 프로세스
Readers-Writers Problem
공유되는 DB에서 readers와 writers process가 있을 때, reader는 동시 접근이 가능하지만 writer는 동시 접근 시 문제가 된다.
따라서 writer는 쓰기 시 데이터베이스에 대해 배타적 접근 권한을 가져야 한다.
1. 우선 순위 활용
first readers-writers problem reader에게 우선 순위를 준다 ⇒ writer에서 starvation 발생 가능
seconde readers-writers problem
writer에게 우선 순위를 준다 ⇒ reader에게 starvation 발생 가능
⇒ 두 case 모두 starvation이 발생하기에, semaphore를 이용해 문제를 해결한다.
2. first readers-writers problem with semaphore
Reader process는 자신 이외의 reader process가 종료되기 전까지wait()을 호출할 수 없음
즉, Writer 프로세스는 Reader 프로세스 모두가 종료될 때까지 대기함을 의미 ⇒ Reader 프로세스가 계속해서 물밀듯이 들어오면 writer 프로세스는 기아(Starvation) 상태에 빠질 수 있음
2. Secondreaders-writers problem withsemaphore
만약writer 프로세스가 오브젝트에 접근하면, 새로운 reader 프로세스는 실행할 수 없음
writer 프로세스에게 우선 순위를 높게 주어 먼저 실행하게 만드는 것
또한 writer 프로세스가 물밀듯이 들어올 경우 reader 프로세스가 기아 상태에 빠질 수 있음
첫번째 readers-writers problem (독자에게 우선권을 주는 문제)에 대해 더 알아보자.
read_count : 얼마나 많은 프로세스가 읽고 있는지 나타내기 위해 사용 read_count = 0 → writer 프로세스 진입
while(true) {
wait(rw_mutex); // 독자로부터 신호가 오면 진입
/* writing is performed */
signal(rw_mutex);
}
while(true) {
wait(mutex); // 공유 자원 접근을 위한 요청
read_count++; // 읽고 있는 프로세스의 수 더하기
if(read_count == 1)
wait(rw_mutex); // 독자 프로세스는 여러 프로세스가 진입이 가능하다.
signal(mutex);
/* reading is performed */
wait(mutex); // 공유 자원 접근을 위한 요청
read_count --;
if (read_count == 0)
signal(rw_mutex);
signal(mutex);
}
Writer 프로세스가 임계 영역에 접근하면 많은 Reader 프로세스는waiting상태에 빠짐
한 개의 Reader 프로세스는rw_mutex에서, 나머지 독자 프로세스는mutex에서 대기
Writer가signal(rw_mutex) 연산을 실행할 때 대기중인 Writer/Reader 프로세스 실행 여부는스케줄러에 의해 결정
어떤 프로세스의 우선 순위를 높이느냐에 따라 해결책이 갈림 ⇒ 독자 프로세스의 우선 순위를 높인다면 첫번째 방법, 작가 프로세스의 우선 순위를 높인다면 두번째 방법이 될 것이다.
독자-작가 문제 프로세스
Dining-Philosophers Problem
테이블에 앉은 철학자는 자신의 양쪽에 놓인 젓가락을 집어야 식사를 할 수 있다.
철학자들에게 제공된 젓가락은 딱 다섯 개이다.
철학자들은 배가 고파지면두 개의 젓가락이 있어야 음식을 먹을 수 있다.
만약 인접한 철학자가 동시에 배고파지면, 한 철학자는 젓가락을 못잡을 것이다.
이 상황은 여러 자원을 여러 프로세스가 공유하고 있는 상황으로, 모두가 아무 것도 할 수 없는 deadlock 상황(교착 상태)이 발생한다.
(철학자 = process, 젓가락 = resource)
Semaphore Solution
while (true) {
wait (chopstick[i]); // Left
wait (chopstick[(i+1) % 5]); // Right
/* eat for a while */
signal (chopstick[i]);
signal (chopstick[(i+1) % 5]);
/* think for a while */
}
각 젓가락에 세마포어를 부여해주는 방식
철학자들은 젓가락을 잡을 때 wait() 연산, 젓가락을 놓을 때 signal() 연산을 실행하여 상호 배제 보장
5명의 철학자가 동시에 배고파지기라도 하면, 그 누구도 양쪽의 젓가락을 집을 수 없음 ⇒데드락과 기아 문제를 해결하지 못한 방법
해결 방법
(1) 최대 4명만 동시에 앉음
(2) 양쪽 젓가락이 가용할 때만 집도록 허용
(3) 비대칭 방법 ⇒ 홀수/짝수 번호별로 다르게 동작
Monitor Solution
모니터를 이용해 해결하는 방법
철학자들은 양쪽의 젓가락이 모두 놓여져 있을 때 젓가락을 집음
철학자들의 상태를 3가지로 구분
enum {THINKING, HUNGRY, EATING} state[5];
이웃들이 Eating이 아닐 때 Eating 상태가 될 수 있다.
(state[i+4)%5] != EATING) and (state[(i+1) % 5] != EATING)
한 철학자가 음식을 먹으려면, 인접한 두 철학자가 eating 상태가 아니어야 한다.
또한, 상태 변수를 이용하여 철학자가 hungry 상태이지만 음식을 먹을 수 없을 때 스스로를 지연시키도록 한다.
class DiningPhilosopherMonitor {
private int numOfPhils;
private State[] state;
private Condition[] self; // Condition Value
private Lock lock;
public DiningPhilosopherMonitor(int num) {
numOfPhils = num;
state = new State[num];
self = new Condition[num];
lock = new ReentrantLock();
for (int i = 0; i < num; i++) {
state[i] = State.THINKING;
self[i] = lock.newCondition(); // Condition
}
}
private int leftOf(int i) {
return (i + numOfPhils - 1) % numOfPhils;
}
private int rightOf(int i) {
return (i + 1) % numOfPhils;
}
private void test(int i) {
if (state[i] == State.HUNGRY && state[leftOf(i)] != State.EATING && state[rightOf(i)] != State.EATING) {
state[i] = State.EATING;
self[i].signal();
}
}
public void pickup(int id) {
lock.lock();
try {
state[id] = State.HUNGRY;
test(id);
if (state[id] != State.EATING) self[id].await();
} catch (InterruptedException e) {
} finally {
lock.unlock();
}
}
public void putdown(int id) {
lock.lock();
try {
state[id] = State.THINKING;
test(leftOf(id));
test(rightOf(id));
} finally {
lock.unlock();
}
}
}
→ 동시에 실행되지만 turn 값에 따라서 임계 구역에 한 process만 진입하고 있으므로 만족한다. 한 process가 CS에 있는 한, 조건이 변하지 않고 유지되므로 나머지 process는 무조건 대기해야 한다.
2. Progress에 대한 요구 조건을 만족하는가?
3. Bounded-waiting이 한없이 길어지지 않는가?
→ 프로세스 Pi는 while문에서 대기하면서 변수 값을 변경하지 않으므로, Pj가 CS를 나오면서 flag[j]를 false로 변경할 때 CS에 진입한다. (1회 대기 → bounded waiting)
→ Pj가 CS를 나오면 다음 CS 진입 process는 대기 중인 Pi가 된다. (Pj가 다시 진입 X → progress)
Peterson의 해결책은 최신 컴퓨터에서는 작동하지 않는다. 시스템 성능을 향상시키기 위해 종속성이 없는 읽기/쓰기 작업을 재정렬할 수 있기 때문이다.
또한 Instruction들의 재배치로 인해 제대로 실행함을 보장할 수 없다.
상호 배제를 유지하는 방법은 적절한 동기화 도구를 사용하는 것이다.
Hardware Support for Synchronization
하드웨어를 사용하여 Critical-Section problem을 해결할 수 있다.
1. Memory Barriers
메모리 장벽은 매우 낮은 수준의 연산으로 일반적으로 Mutual Exclusion 을 보장하는 특수 코드를 작성할 때 커널 개발자만 사용한다.
다음 명령 실행 전 모든 load와 store이 완료됨을 보장하고, reorder되더라도 후속 명령의 실행 전에 저장을 완료하고 그 결과를 모두에게 보여준다.
즉, 메모리 간 변경 사항을 전파해 명령어들의 순서를 보장한다.
2. Hardware Instructions - TAS, CAS
특별한하드웨어 명령으로 원자성을 가진 명령을 추가하는 방법이다.
한 워드의 내용을 검사하고 변경하거나 두 워드의 내용을 원자적으로 교환할 수 있게 한다.
즉,인터럽트 할 수 없는 하나의 단위로 간단하게 크리티컬 섹션을 해결할 수 있다.
test_and_set() : 제일 처음 process만 CS에 진입하도록 함
compare_and_swap(): swapping에 기반하여 two words에 atomic하게 동작하도록 함
example code test_and_set
boolean test_and_set(boolean *target) {
boolean rv = *target;
*target = true;
return tv;
}
do {
while (test_and_set(&lock)); /* do nothing, context switching X */
// 본인의 lock 을 true 로 만들고 진입한다.
/* critical section */
lock = false; // 크리티컬 섹션을 빠져나온 후 false로 만들어 다른 프로세스 진입을 허용
/* remainer section */
} while (true);
example codecompare_and_swap
int compare_and_swap(int *value, int expected, int new_value) {
int temp = *value;
if (*value == expected)
*value = new_value;
return tmp;
}
while (true) {
while (compare_and_swap(&lock, 0, 1) != 0);
/* do nothing */
/* critical section */
lock = 0;
/* remainer section */
3. Atomic Variables
원자적 변수는 기본 데이터 타입(integer, boolean)에 대해 원자적 연산을 제공한다.
경쟁 상황(race condition)이 일어나는 단일 변수에 대해 상호배제(mutual exclusion)를 보장해준다.
원자적 변수를 지원하는 시스템은 원자적 변수에 접근하고 조작하기 위한 기능뿐 아니라 특별한 원자적 데이터 유형을 제공한다.
Mutex Locks
임계구역 문제를 해결하기 위해 상위 수준의 소프트웨어 도구 중 가장 간단한 것이 Mutex Locks이다.
Mutex Locks는 Mutual exclusion으로, 임계구역을 보호하고 경쟁 조건을 방지하기 위해 사용한다.
즉 프로세스는 임계 구역에 들어가기 전에 반드시 lock을 획득해야 하고, 임계구역을 빠져나올 때 lock을 반환해야 한다. 여기서 lock을 획득하는 함수는 acquire()이고, lock을 반환하는 함수는 release()이다. 이 두 함수는 atomic하게 수행되어야 한다.
이 방식의 단점은 바쁜 대기(busy waiting)을 해야 한다.
한 프로세스가 임계 구역에 있는 동안 나머지 프로세스는 계속 조건을 확인하며 loop를 실행해야 한다. 이로 인해 CPU가 낭비된다.
여기에 나온 Mutex Locks은 스핀락(spinlock)이라고도 하는데, 락을 사용할 수 있을 떄까지 프로세스가 회전한다.
이때 스핀락은 context switch이 필요하지 않다.
Semaphore
임계구역 문제를 해결하기 위해 상위 수준의 소프트웨어 도구 중 가장 간단한 것이 Mutex Locks이다.
Semaphore는 Mutex와 유사하게 동작하지만 프로세스들이 자신의 행동을 더 정교하게 동기화할 수 있는 방법을 제공한다.
Semaphore는 wait()(STOP)과 signal()(GO)를 통해 process가 critical section에 진입하는 것을 관리한다.
이는 정수형 변수, 초기화를 제외하고 두 표준 atomic 연산으로만 접근된다. (wait, signal)
공유 자원이 여러 개 있는 상황에서도 적용 가능한 synchronization tool
여러 개의 process가 각각 공유 자원에 접근 가능
binary semaphore & counting semaphore
S : 임계 구역에 진입할 수 있는 process 개수 (사용 가능한 공유 자원의 개수)
signal() : 임계 구역 앞에서 기다리는 process에게 '이제 가도 좋다'고 신호를 주는 함수
wait() : 임계 구역에 들어가도 좋은지, 기다려야 할지 알려주는 함수
wait(S) {
while (S <= 0)
; // busy wait
S--;
}
signal(S) {
S++;
}
→ wait()와 signal() 연산 시 세마포의 정수 값을 변경하는 연산은 반드시 원자적으로 수행되어야 한다.
Semaphore Usage
Counting semaphore
값들은 제한 없는 영역을 가짐
공유 자원이 N 개인 경우 (0이면 unavailable) 가용한 자원의 수로 초기화
wait() 연산 수행하여 세마포 값 줄임
signal() 연산 수행하여 프로세스가 자원 방출할 때 세마포 값 증가
count == 0이면 자원 모두 사용됨
count ≤ 0이면 프로세스는 block됨
Binary semaphore
0 또는 1의 값만 가능
공유 자원이 1개인 경우 mutex lock 대신 사용 가능
Semaphore Implementation
Mutex Locks과 마찬가지로 Semaphore 연산 wait()과 signal() 역시 바쁜 대기 문제(busy waiting)를 가지고 있다.
따라서 wait()과 signal()을 아래와 같이 수정해야 한다. 또한 semaphore를 새롭게 정의한다.
wait() : semaphore 사용을 위해 기다리면 프로세스가 list에 추가됨
busy waiting 대신 프로세스가 스스로 suspend operation (sleep())을 통해 waiting queue로 이동하여 waiting state로 전환
본 포스팅은 공룡책으로 불리는Abraham Silberschatz, Peter B. Galvin, Greg Gagne의 『Operating System Concept 10th』기반으로 정리한 글입니다.
CPU Scheduling Basic Concepts
멀티 프로그래밍을 채택한 O/S에서는 기본적으로 사용
멀티 프로그래밍의 기본적인 목표
CPU 사용률을 최대화하기 위해 프로세스들을 concurrent하게 항상 실행
한 프로세스가 wait할 경우 OS CPU를 뺏은 뒤 다른 프로세스에 할당
⇒ 프로세스는 I/O 요청을 위해 CPU 스케줄링이 필요
CPU I/O Burst 사이클
번갈아가며 실행
프로세스 실행은CPU execution과I/O wait의 사이클로 구성된다.
프로세스 실행은 CPU 버스트(burst)로 시작되고 뒤이어 I/O 버스트가 발생한다.
마지막 CPU 버스트는 또 다른 I/O 버스트가 뒤따르는 대신 실행을 종료하기 위한 요청과 함께 끝난다.
Durations of CPU bursts
I/O-bound program : many short CPU bursts, 입출력 짧게 자주
CPU-bound program : few long CPU bursts
CPU Scheduler
CPU 스케줄러(CPU Scheduler) : 메모리 안의실행 준비를 마친 프로세스 중 하나를 선택하여 CPU로 할당하는 역할을 수행
ready 상태에 있는 프로세스들 중 CPU를 할당해줄 수 있는 프로세스를 선택하는 방법으로 무엇을 채택해야 할까?
Linked List / Binary Tree
FIFO Queue
Priority Queue
→ 큐 내 레코드들은 일반적으로 프로세스의 PCB
Preemptive (선점) and Nonpreemptive (비선점) Scheduling
선점형은 스케줄러에 의해프로세스가 실행 도중에CPU에서 빠져나올 수 있음을 의미
비선점형은프로세스가 CPU에서 실행을 마치고 종료할 때까지나머지 프로세스가대기함을 의미 즉, 프로세스가 terminaiting 상태나 waiting 상태로 변할 때까지 대기
Decision Making for CPU-scheduling
프로세스가 running → waiting 상태로 스위칭
프로세스가 running → ready 상태로 스위칭
프로세스가 waiting → ready 상태로 스위칭
프로세스가 terminates 상태가 될 때
1번과 4번은 프로세스가 자발적으로 CPU에서 빠져나오는, 즉비선점 유형이다. 스케줄링 면에서는 선택의 여지가 없어서 실행에 의해 새로운 프로세스가 반드시 선택되어야 한다.
2번과 3번은스케줄러에 의해 실행 중 CPU에서 빠져나올 수 있어비선점 유형일수도,선점 유형일수도 있다.
Dispatcher
디스패처는 CPU 스케줄러에 의해 선택된 프로세스에게실질적으로 CPU의 제어권을 주는 역할을 수행한다.
스케줄러는 무엇을 변경할지 선택하는 것이고, 디스패처는 변경을 실제로 수행하는 것이다.
CPU 스케줄러 내부에 포함
프로세스의 레지스터를 적재하고(Context Switching) 커널 모드에서 사용자 모드로 전환
프로그램을 다시 시작하기 위해 사용자 프로그램의 적절한 위치로 이동(jump)
Context Switching을 하는데 소요되는 시간을dispactcher latency라고 칭하고, 이 소요 시간을 줄이기 위해 디스패처는 최대한 빨라야 한다.
Dispatcher Latency는 CPU 사용 시간보다 가급적 짧아야 한다.
Scheduling Criteria
CPU 스케줄링 알고리즘별 특성이 다르기에, 상황에 따라 선택해야 한다.
비교하는 데 사용되는 특성에 따라서 알고리즘을 결정하는 데 큰 차이가 발생한다.
Scheduling criteria는 스케줄링 알고리즘 비교를 위한 기준으로, 최선의 알고리즘을 선택하는데 기준점이 된다.
CPU 이용률 ( CPU utilization )
CPU는 바쁜 상태를 유지해야함 → 사용률을 늘려야함
실제 시스템에서는 40%에서 90%까지의 범위를 가져야함
처리량 ( Throughput )
특정 시간 내 많은 양의 프로세스 처리
작업량 측정의 한 방법은 단위 시간당 완료된 프로세스의 개수
총 처리 시간 ( Turnaround time)
프로세스 실행 후 종료까지의 시간을 최소화
대기 시간 = 준비 큐에서 대기하면서 보낸 시간의 합
응답 시간 ( Response time )
첫 응답이 시작되는 데까지 걸리는 시간
중간에 결과가 나온다면 그것이 기준이 됨
응답 시작까지의 걸리는 시간이지 최종 응답 출력까지의 시간이 아님
대기 시간 ( Waiting Time)
하나의 요구를 제출한 후 첫 번째 응답이 나올 때까지 걸리는 시간
프로세스가Ready큐에 상주하는 시간을 최소화
Waiting time을 개선하면 시스템의 효율을 크게 증대
CPU 이용률과 처리량을 최대화하고 총처리 시간, 대기 시간, 응답 시간을 최소화하는 것이 바람직하다.
평균보다는 최대/최소값을 최적화시킨다.
Scheduling Algorithms
Ready queue 내의 어떤 프로세스에게 CPU core를 할당할 것인가의 문제를 해결한다.
FCFS(First-Come, First-Served) Scheduling
먼저 온 프로세스를 먼저 실행하는 방법
비선점 스케줄링 유형
FIFO 큐를 참고하여 만들어진 방법으로 구현이 가장 쉽고 간단
CPU 버스트 타임이 긴 프로세스가 먼저 실행되는 경우waiting time이 크게 늘어나 효율성이 하락
FCFS 알고리즘
SJF(Shortest Job First) Scheduling
도착 순서와 무관하게 짧은 작업을 먼저 수행
크기가 동일할 경우 먼저 도착한 프로세스 실행
선점 유형 or 비선점 유형
다음 프로세스에게 대기 명령을 내리면 비선점 유형
현 프로세스를 중단하고 다음 프로세스를 실행시키면 선점 유형
평균 waiting time 을 최대한 줄일 수 있는 최적의 옵션
다음 프로세스의 CPU burst 시간을 확실히 알 수 없기 때문에 현실적으로 구현하기 어려움
이에 대한 방안으로 다음 프로세스의 CPU burst 시간을예측하여 비슷하게라도구현
실행할 프로세스가 과거에 얼마나 CPU burst 시간을 소요했는지 저장하여 현재 소요할 시간을 예측
그러나 시간을 얼마나 쓰는지 기록하는 것 역시 CPU에 저장되는 것이기 때문에 부담 O
SJF 스케줄링
SRTF(Shortest-Remaining-Time-First) Scheduling
현재실행중인 프로세스보다 다음 프로세스의 실행 시간이 짧다면 바로 다음 프로세스를 실행하는 방법
SJF, SRTF 스케줄링의 경우 계속해서 짧은 실행 시간을 가진 프로세스가 도착하면,긴 실행 시간을 가진 프로세스는 영영 실행하지 못할 가능성이 있음
SRTF 알고리즘
RR(Round-Robin) Scheduling
먼저 들어온 프로세스를 실행하지만,시간 단위(time quantum)에 따라 끊임없이 스위칭하는 선점형 스케줄링 방법
원형 큐(순환 큐)로 처리
평균 waiting 시간을 줄일 수 있으나, 평균 response 시간이 크게 늘어날 수 있음
프로세스의 CPU 버스트 시간이설정한 시간 단위보다 적다면? → 프로세스가 CPU에서자발적으로 탈출하고 스케줄러는ready큐에 있는 다음 프로세스를 실행한다.
프로세스의 CPU 버스트 시간이설정한 시간 단위보다 길면? → O/S에 의해인터럽트와 함께 컨텍스트 스위칭이 발생한 후 다음 프로세스를 바로 실행한다. 그리고 현재 프로세스는ready큐의 끝으로 가 대기한다.
Priority-base Scheduling
각 프로세스에게 우선 순위를 할당하고,우선 순위 순으로 프로세스를 CPU에 할당하는 방법
같은 우선 순위를 가지고 있다면, 먼저 온 프로세스를 실행
CPU burst 시간이 클 때 우선 순위를 낮게 설정할 경우 SJF 스케줄링과 비슷한 결과가 나올 수 있다.
선점 유형 or 비선점 유형
가장 경계해야 할 문제는 기아(starvation) 현상
우선 순위가 낮은 프로세스의 경우 무한정 대기 가능성 존재
이에 대한 방안으로 오랜 기간 대기한 프로세스는 점진적으로 우선 순위를 높이는 방법
Priority-base Scheduling
Multi-Level Queue(MLQ) Scheduling
우선 순위별로 큐를 지정하고, 큐에 따라 각각 다른 스케줄링을 적용하는 방법
새로운 프로세스가 들어왔을 때어느 큐로 분류해야 하는지 애매
Multi-Level Queue(MLQ) Scheduling
MLQ 스케줄링를 보완한 방법
우선 순위별로 큐를 지정하는 것까진 똑같으나, 최하단 우선 순위의 큐를 제외하고는 모두RR 스케줄링을 적용한 방법
처음 실행한 큐는최상단 우선 순위의 큐로 들어감
최상단 우선 순위의 큐에 시간 단위를 가장 낮게 설정하고, 시간 단위 안에 실행한 경우 프로세스는 해당 큐에 유지됨
시간 단위안에 프로세스 실행을 마치지 못한 경우 해당 프로세스의 우선 순위를 한 단계 낮춤
계속해서 시간 단위 내에 실행하지 못한다면 최하단 우선 순위로 내려가 순서대로 실행
실행 시간이 길어 우선 순위가 낮아진 프로세스의 경우 기아 현상이 발생할수도 있음
Thread Scheduling
실제로 OS에 의해서 process가 아닌 kernel-level thread가 스케줄링
user level thread는 thread library에 의해 관리되고 커널은 존재를 모름
→ CPU에서 실행되려면 연관된 kernel level thread에 mapping되어야 한다.
경쟁 범위 Contention Scopre
다대일과 다대다 모델을 구현하는 시스템에서는 thread library는 사용자 수준 스레드를 가용한 LWP 상에서 스케줄한다. 이러한 기법은 동일한 프로세스에 속한 스레드들 사이에서 CPU를 경쟁하기 때문에프로세스 경쟁 범위(process-contention scope, PCS)로 알려져 있다.
CPU상에 어느 커널 스레드를 스케줄 할 것인지 결정하기 위해서 커널은시스템 경쟁 범위(system-contention scope, SCS)를 사용한다.
1. Process Contention Scope (PCS)
User level thread를 스케줄
프로세스 내 스레드 간 CPU core 경쟁
높은 우선 순위를 가진 스레드 선택
실행 중인 스레드 선점
2. System Contention Scope (SCS)
Kernel level thread를 스케줄
시스템 전체 스레드 간 CPU core 경쟁
스레드 라이브러리가 가용 LWP에 스케줄 → OS가 LWP의 kernel thread를 물리적 CPU core에 스케줄
Pthread Scheduling
Pthreads는 다음과 같은 범위의 값을 구분한다.
PTHREAD SCOPE PROCESS : PCS 스케줄링을 사용하여 스레드 스케줄
→ user level 스레드를 가용한 LWP에 스케줄함
PTHREAD SCOPE SYSTEM : SCS 스케줄링을 사용하여 스레드 스케줄
→ 각 user level 스레드에 대한 LWP를 생성하고 연결함 (core에 일대일 매핑)
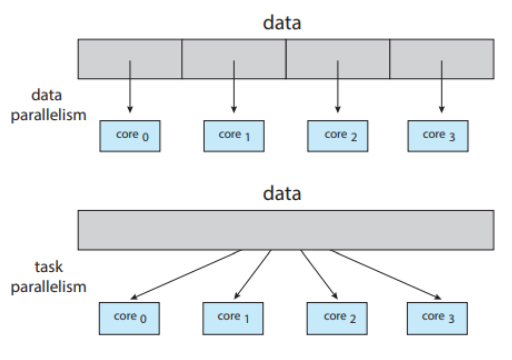
Multi-Processor Scheduling
Multi-Processor는 여러 개의 물리적 프로세서를 제공하는 시스템을 말하며, 각 프로세서에는 하나의 단일 코어 CPU가 포함되어 있다. Processor당 한 core에 여러 CPU가 가용한다면 부하 공유가 가능하다.
다중 처리기는 다음 시스템 아키텍처들에 사용할 수 있다.
Multicore CPU (homogenous)
Multithreaded cores (homogeneous)
NUMA systems (homogeneous)
Heterogeneous multiprocessing
Approaches to Multiple-Processor Scheduling
1. 비대칭 다중 처리기 AMP (asymmetric multiprocessing )
비대칭 (기능적으로 다름) : Master / others
Master server가 모두 처리하며 나머지는 user code만 실행
오직 하나의 코어만 시스템 자료구조에 접근하여 자료 공유의 필요성을 배제하기 때문에 간단함
Master server가 전체 시스템 성능을 저하할 수 있는 병목이 될 수 있음
2. 대칭 다중 처리 SMP (symmetric multi-processing)
독립적으로 작업 가능
CPU마다 똑같은 일 처리 가능
다중 처리기를 지원하기 위한 표준 접근 방식
각 프로세서는 스스로 스케줄링 가능하며 스케줄러가 ready queue를 확인하고 실행할 스레드를 선택함
Multicore Processors
현대 컴퓨터 하드웨어는 동일한 물리적인 칩 안에 여러 개의 처리 코어를 장착하여다중 코어 프로세서 (multicore processor)가 된다.
프로세서가 메모리에 접근할 때 데이터가 가용해지기를 기다리면서 많은 시간을 소비하는메모리 스톨(memory stall)이라고 하는 이 상황은 최신 프로세서가 메모리보다 훨씬 빠른 속도로 작동하기 때문에 주로 발생한다.
현대 프로세스는 메모리보다 속도가 훨씬 빨라서 cache miss가 발생하게 된다.
이러한 상황을 해결하기 위해
둘 이상의 hardware thread를 한 core에 할당
한 hardware thread가 메모리를 기다리며 중단되면 core가 다른 thread로 전환
각 hardware thread는 각 arhictectural state를 유지
OS 입장에서는 hardware thread를 software thread를 실행하는 논리적인 CPU로 보고 스케줄링 진행 (chip multithreading; CMT)
Load Balancing (부하 균등)
SMP
운영체제와 메모리를 공유하는 여러 프로세서가 프로그램을 수행하는 것
시스템의 모든 처리기 사이에 부하가 고르게 배분되도록 시도
멀티프로세서의 이점을 최대한 활용하기 위해서인데, 그렇지 않으면 하나의 프로세서가 idle 상태일 때 다른 프로세서들은 부하가 클 수 있음 → ready queue에서 CPU를 기다리는 상황
Load Balancing
SMP에서 모든 프로세서들의 부하를 동일하게 유지하는 것
각 프로세서별로 자신의 ready queue를 갖는 시스템에서는 필요함
common run queue를 사용하는 system에서는 필요없음
Processor Affinity
스레드에 의해 가장 최근에 접근된 데이터가 그 처리기의 캐시를 채우게 된다. 그 결과 스레드에 의한 잇따른 메모리 접근은 캐시 메모리에서 만족한다.
그렇다면 스레드가 특정 processor에서 실행될 때 캐시 메모리는?
Warm Cache
스레드가 최근 접근한 데이터가 프로세서의 캐시를 채움
스레드에서의 연속적인 메모리 접근은 캐시 메모리에서 처리됨 → warm cache
캐시 무효화 및 다시 채우는 비용이 많이 들기 때문에 SMP를 지원하는 대부분의 운영체제는 스레드를 한 프로세서에서 다른 프로세서로 이주시키지 않고 같은 프로세서에서 계속 실행시키면서 warm cache 를 사용한다.
Process Affinity 형태
1. Soft Affinity
OS는 process가 동일 processor에서 실행되도록 노력함, 보장은 안됨
노력은 하지만 load balancing으로 이주 가능
2. Hard Affinity
system call로 프로세스가 실행될 수 있는 프로세서의 집합을 지정
특정 프로세서에서 실행되도록 보장
메인 메모리 구조가 process affinity에도 영향을 준다.
특정 CPU에 스케줄된 스레드로부터 가까운 메모리를 할당한다.
NUMA-aware인 경우 가까운 메모리에 할당한다.
Heterogeneous Multiprocessing (HMP)
모든 프로세서가 기능 면에서 동이하기에 스레드는 임의 core에서 실행 가능하다.
load balancing, processor affinity, NUMA 등에 따라 메모리 접근 시간이 다르다.
core들이 기능적으로 다를 수 있음
스레드가 특정 목적으로 특정 core에서 실행될 수 있음
task의 특정 요구에 기반해 특정 core에 할당함으로써 전력 소비를 더 잘 관리
Real-Time CPU Scheduling
Real-Time O/S에서의 스케줄링은 Soft Realtime 혹은 Hard Realtime 으로 구성된다.
Soft real-time시스템 :반드시 정해진 시간 내에 실행하는 것은 아니며, 중요 태스크가 먼저 실행된다는 것만 보장
Hard real-time시스템 : 요구 사항이 매우 엄격하여태스크는 반드시 시간 내에 실행되어야 함