이어달리기 프로젝트 회원가입 API를 하게 되면서 공부하게 된 스프링 security & jwt!
공부하면서 알게 된 DispatcherServlet 클래스는Servlet, Spring MVC의 중심이다. DispatcherServlet이 뭔지, 그리고 적용한 예제에 대해 알아보자.
DispatcherServlet이란
Dispatcher Servlet에서 Dispatch의 의미는 급파하다, 파견 등의 의미로 해석해보면받은 요청을 어딘가로 빨리빨리 보내는 서블릿이라는 뜻이다. 또한프론트 컨트롤러라고 불리기도 한다.
과연 어디로 보내는 것이고 프론트 컨트롤러라면 컨트롤러의 종류 중 하나인걸까?
## 서블릿이란?
클라이언트의 요청을 처리하고, 그 결과를 반환하는 Servlet 클래스의 구현 규칙을 지킨 자바 웹 프로그래밍 기술
간단히 말해서, 서블릿이란 자바를 사용하여 웹을 만들기 위해 필요한 기술이다. 클라이언트가 어떠한 요청을 하면 그에 대한 결과를 다시 전송해주어야 하는데, 이러한 역할을 하는 자바 프로그램이다. 예를 들어, 어떠한 사용자가 로그인을 하려고 할 때. 사용자는 아이디와 비밀번호를 입력하고, 로그인 버튼을 누른다. 그때 서버는 클라이언트의 아이디와 비밀번호를 확인하고, 다음 페이지를 띄워줘야 하는데 이러한 역할을 수행하는 것이 바로 서블릿(Servlet)이다. 그래서 서블릿은 자바로 구현 된 *CGI라고 흔히 말한다
(CGI(Common Gateway Interface): CGI는 특별한 라이브러리나 도구를 의미하는 것이 아니고, 별도로 제작된 웹서버와 프로그램간의 교환방식이다)
0. 배경
JAVA 런타임에서는컨트롤러가 존재하지 않는다. 따라서 서블릿 객체를 생성하고, 이를 web.xml에다 일일히 다 등록해줘야 했다.
하지만 웹사이트를 이용해봤다면 알겠지만,우리가 접속하는 페이지는 한두개가 아니다. 게다가 컨트롤러와는 달리서블릿 객체 하나는 하나의 경로만 담당한다. 이렇게 되면 10개보다 더 늘어날 것이고 프로젝트 문서는 온통 서블릿 객체로 넘쳐날 것이다.
서블릿의 단점
1. 높은 의존성
Servlet 객체는 HttpServlet를 확장한 객체이다. 이렇게 되면HttpServlet 기능을 필수로 Override해야 하고,더이상 일반 객체로 사용할 수 없다. 즉,클래스끼리 값을 주고받기가 까다로워진다.
2. 중복되는 작업
모든 서블릿이 공통으로 처리하는 작업이나,가장 우선시 되야하는 작업이 분명 있을 것이다. 이런 것을 서블릿 객체로 처리하기란불가능하고, 매우 까다로울 것이다.
DispatcherServlet은 이러한 단점들을 모두 해소해주고, 간편하게 사용할 수 있다.
1. Controller
서블릿을 더이상HttpServlet을 확장하지 않고, POJO를 사용한다. @Controller 어노테이션을 붙여서 간편히 사용할 수 있으며,의존성이 낮아져서 다른 객체들과 연계가 자유롭다.
Servlet 객체
/* Servlet 객체 */
@WebServlet("/user")
public class testServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// GET 작업 처리
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// POST 작업 처리
}
@Override
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 서블릿 동작 처리
}
}
Controller 객체
@Controller
public class testController {
@PostMapping("/user")
public String userPage() {
// POST 처리
}
@GetMapping("/user")
public String userPage() {
// GET 처리
}
}
2. 2차 컨트롤러 구조
Controller가 생겨났음에도 불구하고,여전히 web.xml에 일일히 등록해야 했다. 하지만 컨트롤러가 다음과 같은 구조를 띄면서 문제는 사라졌다.
위와 같은 구조를 필자는2차 컨트롤러 구조라고 부른다. 기존에 web.xml에 각 컨트롤러를 모두 등록해야 하지만, DispatcherServlet이모든 요청을 받고 세부 경로는 각 Controller에게 뿌려주는 프론트 컨트롤러의 역할을 함으로써,web.xml에 서블릿을 일일히 등록할 필요가 없어졌다.
라이징테스트 원티드 클론코딩 프로젝트를 하면서 멘토님께서 트랜잭션 잘 반영했는지 체크하면 좋겠다는 피드백을 받았다.
이번 기회에 스트링부트에서 트랜잭션 정의와 DB의 트랜잭션을 관리하는 방법을 익히며 현재 Dao단의 쿼리문을 검토하며 적용해볼 예정이다!
Spring Transaction Management
트랜잭션은 완전히 성공하거나완전히 실패하는 일련의 논리적 작업단위이자, 데이터베이스에서 SQL을 실행하는 작업 단위를 뜻한다.
보통 데이터베이스에 데이터 CRUD 연산을 요청할 때 SQL 쿼리를 작성해서 실행한다. 단순하게 하나의 SQL 쿼리 실행이 실패한 경우 문제가 없다. 그러나 여러 건의 데이터를 처리하는 쿼리가 실행되던 중 오류가 발생하는 경우도 찾아온다. 이런 경우 오류 발생 전 완료된 작업은 DB에 저장할 것인지, 혹은 작업 전체를 오류로 판단하여 작업 내용을 원상 복구할지 처리해야한다. 중간에 오류가 발생하면 트랜잭션의 모든 단계를 이전으로 돌리는 것을 롤백이라고 부른다.
스프링부트에서는 DB의 트랜잭션을 처리할 수 있는 기능을 지원한다.
트랜잭션의 성질
원자성 (Atomicity) : 한 트랜잭션 내 실행한 작업들은 하나로 간주한다. 모두 성공하거나 모두 실패한다.
일관성 (Consistency) : 트랜잭션은 일관성 있는 데이터베이스 상태를 유지한다. (Data integrity 만족 등)
격리성 (Isolation) : 동시에 실행되는 트랜잭션들이 서로 영향을 미치지 않도록 격리해야 한다.
지속성 (Durability) : 트랜잭션을 성공적으로 마치면 결과가 항상 저장되어야 한다.
트랜잭션의 종류
1. Global Transactions
드물지만 서로 다른 데이터베이스 간에 트랜잭션이 발생할 수 있는 응용프로그램이 있을 수 있다. 이를 분산 트랜잭션(distributed transaction) 처리라고 한다.
트랜잭션 관리자는 이를 처리하기 위해서 애플리케이션 내에 있을 수 없고 애플리케이션 서버 수준에 있다. JTA 또는 Java Transaction API는 JNDI의 지원과 함께 다른 데이터베이스를 조회하는데 필요하며 트랜잭션 관리자는 분산 트랜잭션의 커밋 또는 롤백을 결정한다. 이는 복잡한 프로세스이며 애플리케이션 서버 수준의 지식을 필요로 한다.
2. Local Transactions
로컬 트랜잭션은 간단한 JDBC 연결과 같은 단일 RDBMS와 애플리케이션 사이에서 발생한다. 로컬 트랜잭션을 사용하면 모든 트랜잭션 코드가 우리 코드 내에 있다.
만약 jdbc를 사용한다면 트랜잭션 관리 API는 JDBC용이다. Hibernate (JPA API 중 하나)를 사용한다면 애플리케이션 서버의 hibernate 트랜잭션 API와 JTA는 global 트랜잭션을 위한 것이다.
@Component
public class BookingService {
private final static Logger logger = LoggerFactory.getLogger(BookingService.class);
private final JdbcTemplate jdbcTemplate;
public BookingService(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Transactional
public void book(String... persons) {
for (String person : persons) {
logger.info("Booking " + person + " in a seat...");
jdbcTemplate.update("insert into BOOKINGS(FIRST_NAME) values (?)", person);
}
}
public List<String> findAllBookings() {
return jdbcTemplate.query("select FIRST_NAME from BOOKINGS",
(rs, rowNum) -> rs.getString("FIRST_NAME"));
}
}
BookingService클래스에 @Component 어노테이션을 추가하여 스프링 빈 클래스로 추가한다. book() 메서드는 JDBC Template을 이용하여 insert 쿼리를 실행한다.
스프링의 트랜잭션은 프로그래밍 방식과 선언적 방식 (어노테이션)의 두가지 방식으로 구분할 수 있다.
프로그래밍 방식의 경우 TransactionTemplate을 활용하거나 직접 PlatformTransacitonManager를 구현한다.
book() 메서드 위에 추가된 @Transactional은 데이터베이스의 트랜잭션 관리를 수행하는 어노테이션이다. 클래스, 메서드위에 이 어노테이션이 추각되면 해당 클래스에 트랜잭션 기능이 적용된 프록시 객체가 생성된다.
이 프록시 객체는 @Transactional이 포함된 메소드가 호출될 경우 PlatformTransactionManager를 사용하여 트랜잭션을 시작하고 정상 여부에 따라 Commit 또는 Rollback한다.
프록시 객체의 프록시 패턴은 해당 클래스가 다른 클래스에 주입되면 Spring에서 내부적으로 target(본체)를 호출하여 대신 주입하는 것이다.
book() 메서드에서 SQL 쿼리 실행 중 실패가 발생하면, 메서드 내에서 실행되었던 쿼리 내용은 모두 Rollback(=원상복귀) 된다. @Transactional 어노테이션 추가만으로 데이터베이스의 트랜잭션을 손쉽게 관리할 수 있다.
@Transactional 어노테이션 속성
@Transactional어노테이션속성설정을변경하여 트랜잭션 설정을 하는 방법을 알아보자.
propagation
트랜잭션 전파를 위한 설정이다. (Optional) 이것은 트랜잭션 동작을 설정하는 데 매우 중요한 속성이다.
REQUIRED (default) : 현재 트랜잭션 지원, 존재하지 않는 경우 새 트랜잭션 생성
REQUIRES_NEW : 새로운 트랜잭션을 생성하고 존재하지 않는 경우 현재 트랜잭션을 일시 중단합니다.
MANDATORY : 현재 트랜잭션을 지원하고 존재하지 않는 경우 예외를 던집니다.
NESTED : 현재 트랜잭션이 있는 경우 중첩된 트랜잭션 내에서 실행
SUPPORTS : 현재 트랜잭션을 지원하지만 존재하지 않는 경우 비트랜잭션으로 실행
isolation
트랜잭션 격리 수준. 트랜잭션이 다른 트랜잭션과 격리되어야 하는 수준을 결정한다.
DEFAULT : 데이터 소스의 기본 격리 수준
READ_UNCOMMITTED :Dirty Read, Non-Repeatable Read 및 Phantom Read가 발생할 수 있음을 나타냅니다. 다른 트랜잭션의 커밋되지 않은 데이터도 읽을 수 있음.
READ_COMMITTED : Dirty Read를 방지하고 반복할 수 없으며 Phantom Read가 발생할 수 있음을 나타냅니다. 커밋된 데이터만 읽음. 반복조회시 커밋 시점에 따라 데이터 상이.
REPEATABLE_READ : Dirty Read와Non-Repeatable Read가 방지되지만 Phantom Read가 발생할 수 있음을 나타냅니다. 반복적으로 조회하여도 동일한 데이터를 보장.
SERIALIZABLE :Dirty Read와Non-Repeatable Read,Phantom Read가 방지될 수 있음을 나타냅니다. 데이터 처리의 직렬화를 보장.
readOnly: 트랜잭션이 읽기 전용인지 또는 읽기/쓰기인지 여부 timeout :트랜잭션 타임아웃(처리 시간초과) rollbackFor: 트랜잭션의 롤백을 발생시켜야 하는 예외(Exception) 클래스의 배열 rollbackForClassName: 트랜잭션의 롤백을 발생시켜야 하는 예외 클래스 이름의 배열 noRollbackFor: 트랜잭션 롤백을 유발하지 않아야 하는 예외 클래스 개체의 배열 noRollbackForClassName: 트랜잭션 롤백을 유발하지 않아야 하는 예외 클래스 이름의 배열
다수의 트랜잭션이 경쟁시 발생할 수 있는 문제
다수의 트랜잭션이 동시에 실행되는 상황에선 트랜잭션 처리방식을 좀 더 고려해야 한다.
예를들어 특정 트랜잭션이 처리중이고 아직 커밋되지 않았는데 다른 트랜잭션이 그 레코드에 접근한 경우 다음과 같은 문제가 발생할 수 있다.
1)Dirty Read
트랜잭션 A가 어떤 값을 1에서 2로 변경하고 아직 커밋하지 않은 상황에서 트랜잭션 B가 같은 값을 읽는 경우 트랜잭션 B는 2가 조회 된다.
트랜잭션 B가 2를 조회 한 후 A가 롤백되면 트랜잭션 B는 잘못된 값을 읽게 된 것이다. 즉, 아직 트랜잭션이 완료되지 않은 상황에서 데이터에 접근을 허용할 경우 발생할 수 있는 데이터 불일치이다.
2) Non-Repeatable Read
트랜잭션 A가 어떤 값 1을 읽었다. 이후 A는 같은 쿼리를 실행할 예정인데, 그 사이에 트랜잭션 B가 값 1을 2로 바꾸고 커밋해버리면 A가 같은 쿼리 두번을 날리는 사이 두 쿼리의 결과가 다르게 되어 버린다.
즉, 한 트랜잭션에서 같은 쿼리를 두번 실행했을 때 발생할 수 있는 데이터 불일치이다. (Dirty Read에 비해서는 발생 확률이 적다.)
3) Phantom Read
트랜잭션 A가 어떤 조건을 사용하여 특정 범위의 값들 [0, 1, 2, 3, 4]을 읽었다.
이후 A는 같은 쿼리를 실행할 예정인데, 그 사이에 트랜잭션 B가 같은 테이블에 값 [5, 6, 7]을 추가해버리면 A가 같은 쿼리 두번을 날리는 사이 두 쿼리의 결과가 다르게 되어 버린다.
즉, 한 트랜잭션에서 일정 범위의 레코드를 두번 이상 읽을 때 발생하는 데이터 불일치이다.
첫번째 단계는 승인 요청을 생성하여 애플리케이션을 식별하는 매개변수를 설정하고 사용자에게 애플리케이션에 부여하라는 요청을 정의합니다.
## 공식문서 Google의 OAuth 2.0 엔드포인트는 https://accounts.google.com/o/oauth2/v2/auth에 있습니다. 이 엔드포인트는 HTTPS를 통해서만 액세스할 수 있습니다. 일반 HTTP 연결은 거부됩니다. Google 승인 서버는 웹 서버 애플리케이션에 다음과 같은 쿼리 문자열 매개변수를 지원합니다.
# 매개변수 client_id (필수) 애플리케이션의 클라이언트 ID입니다.
redirect_uri (필수) 사용자가 승인 흐름을 완료한 후 API 서버가 사용자를 리디렉션하는 위치를 결정합니다. 이 값은 클라이언트의 API에서 구성한 OAuth 2.0 클라이언트에 대해 승인된 리디렉션 URI 중 하나와 정확히 일치해야 합니다.
response_type (필수) Google OAuth 2.0 엔드포인트에서 승인 코드를 반환할지 여부를 결정합니다. 웹 서버 애플리케이션의 매개변수 값을 code로 설정합니다.
scope (필수) 애플리케이션이 사용자를 대신하여 액세스할 수 있는 리소스를 식별하는 공백으로 구분된 범위 목록입니다. 이러한 값은 Google이 사용자에게 표시하는 동의 화면에 알립니다. 범위를 사용하면 애플리케이션이 필요한 리소스에 대한 액세스만 요청하는 동시에 사용자가 애플리케이션에 부여하는 액세스 양을 제어할 수 있습니다.
access_type (권장) 사용자가 브라우저에 없을 때 애플리케이션이 액세스 토큰을 새로고침할 수 있는지 여부를 나타냅니다. 유효한 매개변수 값은 기본값인 online와 offline입니다. 이 값은 애플리케이션이 처음 승인 코드를 토큰으로 교환할 때 갱신 토큰 및 액세스 토큰을 반환하도록 Google 승인 서버에 지시합니다.
state (권장) 애플리케이션이 승인 요청과 승인 서버의 응답 간에 상태를 유지하는 데 사용하는 문자열 값을 지정합니다. 이 매개변수를 사용하여 사용자를 애플리케이션의 올바른 리소스로 안내하거나, nonce를 전송하고, 크로스 사이트 요청 위조를 완화할 수 있습니다. redirect_uri을 추측할 수 있으므로 state 값을 사용하면 수신 연결이 인증 요청의 결과임을 보장할 수 있습니다.
application.yml에 발급받은 client id, client secret key 등을 등록해준다.
노출되면 보안 상 문제가 생기므로 코드에 직접 추가하지 않고 yml 파일에 불러와서 사용해준다.
서버 측에서는 구글 소셜 로그인 페이지로 리디렉션하려면 어떻게 URL을 구성해야 하는지 확인한다.
Google의 OAuth 2.0 서버는 사용자를 인증하고 애플리케이션이 요청된 범위에 액세스할 수 있도록 사용자의 동의를 얻는다. 지정한 리디렉션 URL을 사용하여 응답이 애플리케이션에 다시 전송된다.
URL을 구성하기 위해 Config 파일에 코드를 추가해주었다.
@Component
public class ConfigUtils {
@Value("${google.auth.url}")
private String googleAuthUrl;
@Value("${google.login.url}")
private String googleLoginUrl;
@Value("${google.redirect.uri}")
private String googleRedirectUrl;
@Value("${google.client.id}")
private String googleClientId;
@Value("${google.secret}")
private String googleSecret;
@Value("${google.auth.scope}")
private String scopes;
public String googleInitUrl() {
Map<String, Object> params = new HashMap<>();
params.put("client_id", getGoogleClientId());
params.put("redirect_uri", getGoogleRedirectUri());
params.put("response_type", "code");
params.put("scope", getScopeUrl());
// 파라미터를 형식에 맞춰 구성해주는 함수
String paramStr = params.entrySet().stream()
.map(param -> param.getKey() + "=" + param.getValue())
.collect(Collectors.joining("&"));
return getGoogleLoginUrl()
+ "/o/oauth2/v2/auth"
+ "?"
+ paramStr;
}
public String getGoogleAuthUrl() {
return googleAuthUrl;
}
public String getGoogleLoginUrl() {
return googleLoginUrl;
}
public String getGoogleClientId() {
return googleClientId;
}
public String getGoogleRedirectUri() {
return googleRedirectUrl;
}
public String getGoogleSecret() {
return googleSecret;
}
// scope의 값을 보내기 위해 띄어쓰기 값을 UTF-8로 변환하는 로직 포함
public String getScopeUrl() {
return scopes.replaceAll(",", "%20");
}
}
https://accounts.google.com/o/oauth2/v2/auth?scope=profile&response_type=code&client_id="할당받은id"&redirect_uri="access token 처리" 로 Redirect URL을 생성하는 로직을 구성한다.
application.yml에 @Value에 해당하는 값과 일치하지 않게 적으면 인식을 못한다.
3단계 : 소셜 로그인 이후 요청 처리
이전에 구글에 등록해뒀던 redirect api를 controller에서 개발한다.
소셜 로그인 결과로 받아온 일회성 코드 (상단의 사진)를 보내서 서드파티 (Thrid Party, 제3자 즉 구글)로부터 액세스 토큰을 받아오고, 그 액세스 토큰을 다시 보내 서드파티에 저장된 사용자 정보를 받아오는 일련의 과정을 거칠 것이다.
그 과정의 결과로 다시 서버에 정보를 요청할때 필요한 accessToken, 개발 중인 서버에서 회원 인가처리를 할 jwtToken, 그리고 추후에 조회등에 필요한 userIdx등의 정보를 받아올 것이다.
먼저 일회성 토큰을 받은 후 해당 일회성 토큰을 가지고 Access Token을 발급받기 위한 Request 모델이다.
@Getter
@Setter
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class GoogleLoginReq {
private String clientId; // 애플리케이션의 클라이언트 ID
private String redirectUri; // Google 로그인 후 redirect 위치
private String clientSecret; // 클라이언트 보안 비밀
private String responseType; // Google OAuth 2.0 엔드포인트가 인증 코드를 반환하는지 여부
private String scope; // OAuth 동의범위
private String code;
private String accessType; // 사용자가 브라우저에 없을 때 애플리케이션이 액세스 토큰을 새로 고칠 수 있는지 여부
private String grantType;
private String state;
private String includeGrantedScopes; // 애플리케이션이 컨텍스트에서 추가 범위에 대한 액세스를 요청하기 위해 추가 권한 부여를 사용
private String loginHint; // 애플리케이션이 인증하려는 사용자를 알고 있는 경우 이 매개변수를 사용하여 Google 인증 서버에 힌트를 제공
private String prompt; // default: 처음으로 액세스를 요청할 때만 사용자에게 메시지가 표시
}
다음은 일회성 토큰을 통해 얻은 Response 모델이다.
@Data
@AllArgsConstructor
@NoArgsConstructor
public class GoogleLoginRes {
private String accessToken; // 애플리케이션이 Google API 요청을 승인하기 위해 보내는 토큰
private String expiresIn; // Access Token의 남은 수명
private String refreshToken; // 새 액세스 토큰을 얻는 데 사용할 수 있는 토큰
private String scope;
private String tokenType; // 반환된 토큰 유형(Bearer 고정)
private String idToken;
}
다음으로 구글로 액세스 토큰을 활용해 JWT의 Payload 부분인 구글에 등록된 사용자 정보에 관한 model이다.
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class GetGoogleRes {
private String jwtToken;
private int userIdx;
private String accessToken;
private String tokenType;
}
1) /users/googleLogin
Service 구현 없이 하나의 Controller function 안에서 로직을 구현하였다.
/**
* 구글로그인 API
* [GET] /users/googleLogIn
* @return BaseResponse<PostLoginRes>
*/
@ResponseBody
@GetMapping("/googleLogin")
public ResponseEntity<Object> moveGoogleInitUrl() {
String authUrl = configUtils.googleInitUrl();
URI redirectUri = null;
try {
redirectUri = new URI(authUrl);
HttpHeaders httpHeaders = new HttpHeaders();
httpHeaders.setLocation(redirectUri);
return new ResponseEntity<>(httpHeaders, HttpStatus.SEE_OTHER);
} catch (URISyntaxException e) {
e.printStackTrace();
}
return ResponseEntity.badRequest().build();
}
구글 로그인 페이지 창으로 인도하는 API이다.
client Id, redirect Url, response type, scope과 같은 파라미터를 형식에 맞춰서 구성을 한뒤, yml에 설정한 redirect Login Url과 함께 담아 반환해준다. 즉 구글 로그인 페이지가 보여지게 한다.
상단의 redirectUri는 http Header에 담아진다. 이를 ResponseEntity 형식으로 감싸주고 반환한다.
HttpHeaders
Header에 원하는 방식으로 key-value값을 설정해서 보낼 수 있는 객체이다.
클라이언트와 서버가 요청 또는 응답으로 부가적인 정보를 전송할 수 있도록 한다.
ResponseEntity
일반적인 API는 반환하는 리소스에 Value만 있지 않으며, 상태 코드, 응답 메세지 등이 포함될 수 있다.
ResponseEntity는 client가 보내는 여러가지 응답 내용을 규격에 맞게 한번 감싸주는 역할을 한다.
같은 역할로는 @ResponseBody 어노테이션이 있다.
HttpEntity를 상속받고 있는 클래스이다.
Postman으로 테스트해본 결과,
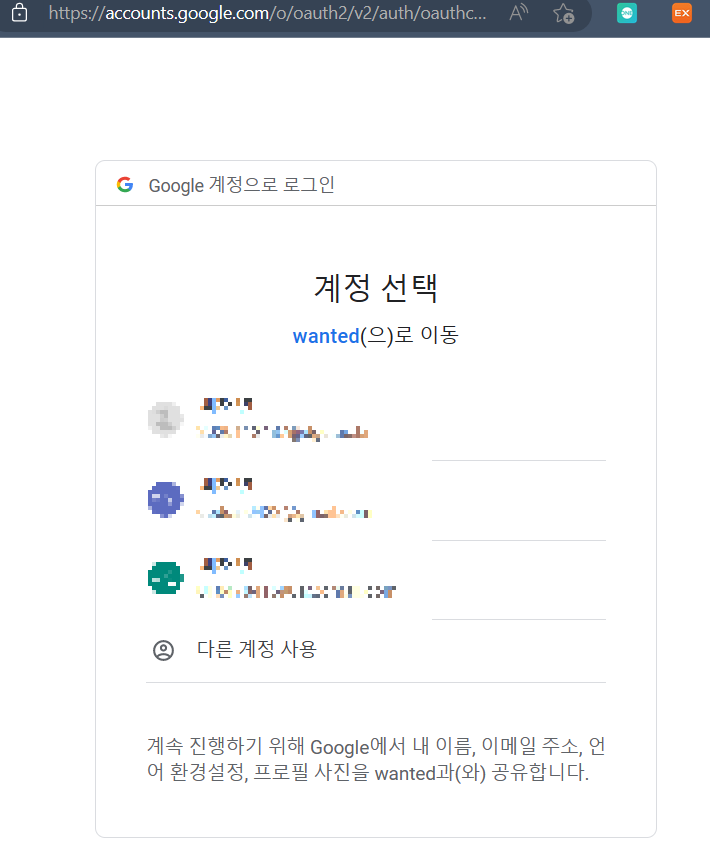
localhost:9000/users/googleLogin으로 request하면 일련의 과정을 거쳐 소셜 로그인 페이지가 렌더링된다.
브라우저에서 확인해보면,
곧바로 소셜 로그인 페이지로 리다이렉트되어 저장되어있는 프로필 페이지가 렌더링되는 것을 확인할 수 있다.
프로필을 선택하고 나면 이전에 남은 로그인 처리를 진행할 redirect_uri로 지정했던 url로 리다이렉트된다.
상단의 코드 파라미터가 추후에 사용할 일회성 코드이다.
2) /users/login/redirect
/**
* Social Login API Server 요청에 의한 callback 을 처리
* @param code API Server 로부터 넘어오는 code
* @return GetGoogleRes
*/
@ResponseBody
@GetMapping("/login/redirect")
public BaseResponse<GetGoogleRes> redirectGoogleLogin(@RequestParam("code") String authCode) {
// HTTP 통신을 위해 RestTemplate 활용
RestTemplate restTemplate = new RestTemplate();
GoogleLoginReq requestParams = GoogleLoginReq.builder()
.clientId(configUtils.getGoogleClientId())
.clientSecret(configUtils.getGoogleSecret())
.code(authCode)
.redirectUri(configUtils.getGoogleRedirectUri())
.grantType("authorization_code")
.build();
try {
// Http Header 설정
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<GoogleLoginReq> httpRequestEntity = new HttpEntity<>(requestParams, headers);
ResponseEntity<String> apiResponseJson = restTemplate.postForEntity(configUtils.getGoogleAuthUrl() + "/token", httpRequestEntity, String.class);
// ObjectMapper를 통해 String to Object로 변환
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setPropertyNamingStrategy(PropertyNamingStrategy.SNAKE_CASE);
objectMapper.setSerializationInclusion(JsonInclude.Include.NON_NULL); // NULL이 아닌 값만 응답받기(NULL인 경우는 생략)
GoogleLoginRes googleLoginResponse = objectMapper.readValue(apiResponseJson.getBody(), new TypeReference<GoogleLoginRes>() {});
// 사용자의 정보는 JWT Token으로 저장되어 있고, Id_Token에 값을 저장한다.
String jwtToken = googleLoginResponse.getIdToken();
// JWT Token을 전달해 JWT 저장된 사용자 정보 확인
String requestUrl = UriComponentsBuilder.fromHttpUrl(configUtils.getGoogleAuthUrl() + "/tokeninfo").queryParam("id_token", jwtToken).toUriString();
String resultJson = restTemplate.getForObject(requestUrl, String.class);
// 랜덤 문자열
String alphaNum = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";
String Num = "0123456789";
int alphaNumLength = alphaNum.length();
int numLength = Num.length();
Random random = new Random();
StringBuffer code = new StringBuffer();
for (int i = 0; i < 8; i++) {
code.append(alphaNum.charAt(random.nextInt(alphaNumLength)));
}
StringBuffer phoneNum = new StringBuffer();
phoneNum.append("010");
for (int i = 0; i < 8; i++) {
phoneNum.append(alphaNum.charAt(random.nextInt(numLength)));
}
if(resultJson != null) {
GoogleLoginDto userInfoDto = objectMapper.readValue(resultJson, new TypeReference<GoogleLoginDto>() {});
GetGoogleReq getGoogleReq = new GetGoogleReq(userInfoDto.getName(), userInfoDto.getEmail(), phoneNum.toString(), code.toString(), userInfoDto.getPicture());
GetGoogleRes getGoogleRes = userService.createSocialUser(getGoogleReq);
getGoogleRes.setAccessToken(googleLoginResponse.getAccessToken());
getGoogleRes.setTokenType(googleLoginResponse.getTokenType());
return new BaseResponse<>(getGoogleRes);
}
else {
throw new Exception("Google OAuth failed!");
}
}
catch (Exception e) {
e.printStackTrace();
}
return new BaseResponse<>(BAD_REQUEST);
}
전체 코드이다. 부분별로 나눠서 살펴보자.
// HTTP 통신을 위해 RestTemplate 활용
RestTemplate restTemplate = new RestTemplate();
GoogleLoginReq requestParams = GoogleLoginReq.builder()
.clientId(configUtils.getGoogleClientId())
.clientSecret(configUtils.getGoogleSecret())
.code(authCode)
.redirectUri(configUtils.getGoogleRedirectUri())
.grantType("authorization_code")
.build();
사용자가 로그인하려고 클릭을 하면 구글에서 accessToken을 발급받기 위해 미리 설정한 uri로 리다이렉트된다.
try문 전까지 보면 우선 HTTP 통신을 위해 RestTemplate을 활용하였다. (보통 Config에 함수를 추가해준다.)
그리고 일회성 토큰으로 accessToken을 발급받기 위해 GoogleLoginReq 바디에 알맞게 client Id, clientSecret, auth code, redirect Uri, 권한 코드와 같은 파라미터들을 담아준다.
// HTTP 통신을 위해 RestTemplate 활용
RestTemplate restTemplate = new RestTemplate();
GoogleLoginReq requestParams = GoogleLoginReq.builder()
.clientId(configUtils.getGoogleClientId())
.clientSecret(configUtils.getGoogleSecret())
.code(authCode)
.redirectUri(configUtils.getGoogleRedirectUri())
.grantType("authorization_code")
.build();
try문부터 살펴보면, Http 헤더를 설정한다. 헤더에 상단에 파라미터를 담은 모델, 즉 일회성 토큰을 통하여 accessToken을 발급받을 준비를 한다.
// ObjectMapper를 통해 String to Object로 변환
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setPropertyNamingStrategy(PropertyNamingStrategy.SNAKE_CASE);
objectMapper.setSerializationInclusion(JsonInclude.Include.NON_NULL); // NULL이 아닌 값만 응답받기(NULL인 경우는 생략)
GoogleLoginRes googleLoginResponse = objectMapper.readValue(apiResponseJson.getBody(), new TypeReference<GoogleLoginRes>() {});
// 사용자의 정보는 JWT Token으로 저장되어 있고, Id_Token에 값을 저장한다.
String jwtToken = googleLoginResponse.getIdToken();
// JWT Token을 전달해 JWT 저장된 사용자 정보 확인
String requestUrl = UriComponentsBuilder.fromHttpUrl(configUtils.getGoogleAuthUrl() + "/tokeninfo").queryParam("id_token", jwtToken).toUriString();
String resultJson = restTemplate.getForObject(requestUrl, String.class);
ObjectMapper를 활용해서 String을 Object로 반환해주고,
일회성 토큰을 통해 얻은 Access Token이 담긴 Response 모델을 읽어온다.
이 모델에 담긴 사용자의 Id Token값을 따로 저장한다.
이 Jwt Token을 Uri에 전달하여 저장된 사용자 정보인지 확인을 하고, Object값으로 result값을 받아온다.
if(resultJson != null) {
GoogleLoginDto userInfoDto = objectMapper.readValue(resultJson, new TypeReference<GoogleLoginDto>() {});
GetGoogleReq getGoogleReq = new GetGoogleReq(userInfoDto.getName(), userInfoDto.getEmail(), phoneNum.toString(), code.toString(), userInfoDto.getPicture());
GetGoogleRes getGoogleRes = userService.createSocialUser(getGoogleReq);
getGoogleRes.setAccessToken(googleLoginResponse.getAccessToken());
getGoogleRes.setTokenType(googleLoginResponse.getTokenType());
return new BaseResponse<>(getGoogleRes);
}
else {
throw new Exception("Google OAuth failed!");
}
result값이 null이 아니라면 objectMapper를 통해 GoogleLoginDto에 사용자의 정보 (userInfoDto)를 담아온다.
DB에 반영하기 위해 userInfoDto에 있는 값을 활용하여 GetGoogleReq를 생성한다.
이번 프로젝트에서는 유저의 비밀번호와 전화번호는 not null로 설정했기에 랜덤으로 값을 생성해준다.
다시 한번 localhost:9000/users/googleLogin에 들어가 로그인을 시도해보면..
다음과 같이 잘 되는 것을 확인할 수 있다!
유저를 생성할 때 사용한 jwtService의 createJwt 메소드를 사용해서 jwtToken도 발급해주었다.
DB에도 정상적으로 잘 반영된 것을 확인할 수 있다!
저번 GetIT 프로젝트에서도 구글, 네이버 소셜 로그인을 구현했으나 내 담당 API가 아니었고, 그렇기에 이번 라이징 테스트 때 꼭 구현해보고자 다짐했었다.
차근차근 공식 문서와 멋진 블로그 선배림들 자료들을 통하여 단계별로 짚고 넘어가서 확실히 이해할 수 있었다!
이번 이어달리기 프로젝트 때 맡게 된다면 프로젝트 구조를 명확히 하여 util, Controller, Service단 각각 역할을 구분지어 가독성 있는 API를 짜고 싶다.
릴레이션의 분해로 인해 릴레이션 간의 연산(JOIN 연산) 증가되어 질의에 대한 응답 시간이 느려질 수 있다.
정규화를 수행한다는 것은 데이터를 결정하는 결정자에 의해 함수적 종속을 가지고 있는 일반 속성을 의존자로 하여 입력/수정/삭제 이상을 제거하는 것이다. 데이터의 중복 속성을 제거하고 결정자에 의해 동일한 의미의 일반 속성이 하나의 테이블로 집약되므로 한 테이블의 데이터 용량이 최소화되는 효과가 있다.
따라서 정규화된 테이블은 데이터를 처리할 때 속도가 빨라질 수도 있고 느려질 수도 있는 특성이 있다.
조회를 하는 SQL 문장에서 조인이 많이 발생하여 이로 인한 성능저하가 나타나는 경우에 반정규화 적용이 필요하다.
반정규화(De-normalization, 비정규화)
데이터베이스의 성능 향상을 위하여, 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법이다.
반정규화는조회(select) 속도를 향상시키지만, 데이터모델의 유연성은 낮아진다.
반정규화의 대상
정규화에 충실하여 종속성, 활용성은 향상 되었지만 수행속도가 느려진 경우
다량의 범위를 자주 처리해야하는 경우
특정 범위의 데이터만 자주 처리하는 경우
요약/집계 정보가 자주 요구되는 경우
테이블에 지나치게 조인을 많이 사용하게 되어 데이터를 조회하는 것이 기술적으로 어려울 경우
반정규화 기법
계산된 컬럼 추가 배치 프로그램으로 총판매액, 평균잔고, 계좌평가를 미리 계산하고 그 결과를 특정 칼럼에 추가한다.
테이블 수직 분할 하나의 테이블의 두 개 이상의 테이블로 분할한다. 즉, 칼럼을 분할하여 새로운 테이블을 만드는 것이다.
흔히 백엔드 개발자들이 사용하는 MySQL이라 부르는 것은 MySQL 서버라고 부를 수 있다.
MySQL 서버는 두뇌 역할을 하는 MySQL실행 엔진이 있고, 손 발 역할을 하는 스토리지 엔진으로 구성된다.
이 둘은 핸들러 API를 통해 서로 통신을 주고 받는다.
쿼리의 실행 과정을 통해 아키텍처에 대해 알아보자.
간단한 join문으로 구성된 쿼리문을 실행한다.
select u.userIdx, u.userName, b.buyList from Buy
left join User as u on u.userIdx = b.userIdx
1. 쿼리 파서 (Parser)
출처 : http://www.hydromatic.net/wiki/FarragoParser
사용자가 SQL 쿼리문을 날리게 되면 쿼리 파서가 요청을 수행한다.
이 쿼리 파서는 SQL 문장을 트리의 형태로 파싱한다.
이 트리 안에 있는 각각의 요소는 MySQL이 인지할 수 있는 최소한의 단위인 Token으로 파싱이 된다.
SQL 문법 오류 여부를 확인하고 예외가 있다면 예외 메세지를 반환한다.
2. 전처리기 (PreProcessor)
다음으로 전처리기에 파서 트리 데이터가 전달된다.
전처리기는 예약어를 제외한 Token을 검사해서 데이터베이스에 실제로 객체가 존재하는지, 실제로 그 객체에 사용자가 접근할 수 있는지 권한을 검증한다.
3. 옵티마이저 (QueryOptimizer)
전처리기에서 수행된 데이터를 바탕으로 옵티마이저에게 전달한다.
옵티마이저는 파서 트리를 실행 계획으로 바꾸는 역할을 한다. 가장 효율적인 방법으로 SQL을 수행할 최적의 처리 경로를 생성해주는 것을 목적으로 한다.
1. 데이터 접근 방법 결정 2. join 등 쿼리 재작성 및 실행 3. 테이블 접근/스캔 순서 결정하여 사용할 인덱스 선택
이런 옵티마이저는 크게 두 종류로 구분할 수 있다.
비용 기반 최적화와 규칙 기반 최적화로 나눌 수 있는데 전자는 MySQL에 존재하는 다양한 통계 정보를 활용해 수행 계획을 수립, 후자는 동일한 SQL이면 항상 동일한 SQL 실행 계획을 수립하는 것이다.
MySQL 포함한 대부분의 RDBMS는 비용 기반 최적화로 진행된다.
비용 기반 최적화
SQL문을 처리하는데 필요 비용이 가장 적은 실행 계획을 선택하는 방식이다.
비용이란 SQL문을 처리하기 위해 예상되는 소유시간 또는 자원 사용량을 의미하며 비용 기반 최적화는 테이블, 인덱스, 칼럼 등의 다양한 객체 통계정보와 시스템 통계정보 등을 이용한다.
비용기반은 통계정보가 없는 경우 불확실한 실행계획을 생성 할 수 있으므로 정확한 통계정보를 유지하는 것이 중요하다.
# 통계 정보란? (MySQL) 대략의 레코드 건수와 인덱스의 유니크한 값의 개수. 벤더마다 약간씩 차이가 있다. Memory 테이블은 별도 통계 정보가 없으며, MyISAM과 InnoDB의 테이블과 인덱스 통계 정보는 아래와 같이 확인 할 수 있다.
SHOW TABLE STATUS LIKE 'user_ldap_list'; SHOW INDEX FROM user_ldap_list;
# 통계정보 수집시 고려사항
시간 : 시스템 부하가 적은 날짜와 시간을 산정해 수집
샘플 크기 : 데이터베이스와 세그먼트의 크기에 비례해 일정 부분만 추출
정확성 : 오브젝트의 데이터와 통계정보의 데이터가 근접해야 함
안정성 : 통계정보 수집으로 인한 데이터베이스 성능 저하를 최소화해야 함
# 실행 계획이란? SQL에서 요구한 사항을 처리하기 위한 절차와 방법 실행계획에서 표시되는 내용 및 형태는 벤더마다 약간 차이는 있지만 실행계획이 SQL 처리를 위한 절차와 방법을 의미한다는 기본적인 사항은 모두 동일하다.
실행 계획은 여러 단계로 이뤄져 있는데 (스텝) 각각 스텝에서 어떤 명령이 수행되었고 몇 건의 데이터가 처리되었으며 얼마만큼의 비용과 시간이 소요되었는지를 표시한다.
규칙 기반 최적화
우선순위가 높은 규칙이 적은 일량으로 해당 작업을 수행하는 방법이다.
규칙 기반 최적화 옵티마이저가 실행계획을 생성할 때 참조하는 정보에는 SQL문을 실행하기 위해서 이용 가능한 인덱스 유무와 (유일, 비유일, 단일, 복합 인덱스) 종류, SQL문 에서 사용하는 연산자(=, <, <>, LIKE, BETWEEN 등)의 종류 그리고 SQL문에서 참조하는 객체(힙, 테이블, 클러스터 테이블 등)의 종류 등이 있다.
규칙 기반은 인덱스를 이용한 액세스 방식이 전체 테이블 액세스 방식보다 우선순위가 높으므로이용 가능한 인덱스가 존재하다면 항상 인덱스를 사용하는 실행계획을 생성하게된다. join 순서를 결정할 때는 join 컬럼 인덱스의 존재 유무가 중요한 판단기준이다.
규칙 기반은 정해진 규칙에 따라 만들어졌을때 BETWEEN 의 현실적인 데이터의 건수 등을 측정을 예측하지못한다.
4. 실행 엔진 (Query Executioin Engine)
다음으로 실행 엔진이다.
옵티마이저에서의 실행계획은 실행 엔진으로 전달되어 스토리지 엔진과 통신을 하여 데이터를 읽어오는 작업을 수행한다.
스토리지 엔진은 실행 엔진의 요청을 처리하기 위한 디스크로부터 데이터를 읽고 쓰는 작업을 한다. 실행 계획대로 각 핸들러에게 요청해서 받은 결과를 또 다른 핸들러 요청의 입력으로 연결하는 역할을 수행한다.
MySQL엔진과 다르게 여러개를 동시에 사용할 수 있다.
5. 핸들러(Storage Engine)
핸들러는 MySql 서버의 가장 밑단에서 MySql 실행 엔진의 요청에 따라 데이터를 디스크로 저장하고 디스크로부터 읽어오는 역할을 담당한다. 스토리지 엔진을 의미한다.
MySQL 엔진은 SQL interface, Parser, Preprocessor, Optimizer, Cache와 Buffer로 구성된다.
InnoDB 스토리지 엔진은 Transaction, Buffer pool, Clustering index, MVCC, Foreign key, Deadlock 감지 등이 있다.
MySQL 8.0 이후로부터 InnoDB 스토리지 엔진을 기본 엔진으로 사용하고 트랜잭션을 제공한다.
* InnoDB 스토리지 엔진
InnoDB 엔진(버퍼 풀, Undo log)과 디스크로 구성된다.
Set GLOBAL TRANSACTION ISOLATION
LEVEL REPEATABLE READ;
상단과 같이 트랜잭션 레벨을 repeatable read로 설정하고 insert문을 활용하여 데이터를 삽입하면 버퍼풀과 디스크에 해당 데이터가 같이 들어간 것을 확인할 수 있다. 이는 버퍼풀이 디스크의 데이터값을 캐싱했다는 것으로 확인할 수 있다.
다음으로 삽입한 데이터를 수정하고 커밋하면, 업데이트한 데이터가 버퍼풀에 반영이 되었고 이전의 데이터는 Undo Log에 추가된다.
디스크에 있는 데이터는 버퍼풀에서 쓰기 작업이 지연되고 있는 상태라면 이전의 데이터로 기록이 되고, 쓰기 작업이 일괄적으로 처리된 상태라면 업데이트된 데이터가 기록된다.
Undo Log에 있는 트랜잭션 Id가 있는데, 이는 실행한 트랜잭션의 id를 의미한다. (순차적으로 증가한다)
버퍼풀
버퍼풀은 데이터 캐싱하고 버퍼링시켜서 데이터를 읽고 쓰는 작업을 빠르게 한다.
MVCC (트랜잭션 동시성을 제어하는 방법)
하나의 레코드에 대해 여러 개의 버전을 관리 (트랜잭션 id)
잠금 없는 일관된 읽기를 제공한다.
-> MVCC, 정렬 처리방식, 복제는 다음 포스팅에서 더 다뤄보기!!
참고 - https://velog.io/@zerodin/%EC%98%B5%ED%8B%B0%EB%A7%88%EC%9D%B4%EC%A0%80%EC%99%80-%EC%8B%A4%ED%96%89%EA%B3%84%ED%9A%8D - https://youtu.be/8PRkLItDwXQ
Caused by: java.net.SocketTimeoutException: connect timed out
라는 에러가 떠서, 관련 CS 지식 타임아웃에 대해 정리해보려고 한다.
스프링부트 API 제작 후 빌드해서 테스트하려고 하는데 직전까지만 해도 잘 돌아가던 빌드가 왜 안되었을까?
.
.
인줄 알았으나 그냥 경고 표시였다.
이번 기회에 타임아웃에 대해 제대로 알고 가보자.
서버 간 통신이 많아지는 MSA 구조가 주목받으면서내부 시스템 안에서도 서로 클라이언트와 서버가 되어 데이터를 주고 받는 비중이 점점 커지고 있다. 이런 상황에서 통신을 요청하는 클라이언트는 다양한 Timeout 오류를 만날 수 있는데, 이런 Timeout에 대한 종류를 잘 구별한다면 각각의 상황에 따라 구분해서 처리할 수 있다.
타임아웃
프로그램이 특정한 시간 내 성공적으로 수행되지 않아 진행이 자동적으로 중단되는 것
응답을 무한정 기다릴 수 없기 때문에 기다릴 시간을 정해야 함
타임아웃 사례
Socket(양방향 통신), Http(단방향 통신)에서 다양하게 활용
JDBC
JDBC Driver Type4는 소켓을 사용하여 DBMS에 연결하는 방식
Connection Timeout : DB 커넥션 요청을 했으나, 특정 시간 내 연결이 안될 때
채팅 프로그램
Socket Timeout : 채팅 프로그램에서 서버로부터 특정 시간 응답이 없을 때
WEB
Connection Timeout : 클라이언트에서 서버로 request를 날렸을 때 연결되지 않은 상태로 특정시간 이상 대기
관련 패키지
java.net
HttpClient
1) java.net 패키지
네트워킹 응용 프로그램을 구현하기 위한 클래스를 제공하는 패키지
java.net 패키지는 크게 두 섹션으로 나뉨
저수준 API
Addresses : 네트워크 식별자 ex) IP 주소
Sockets : 기본 양방향 데이터 통신 메카니즘
Interfaces : 네트워크 인터페이스
고수준 API
URIs : Universal Resource Identifiers
URLs : Universal Resource Locators
Connections : URL이 가리키는 리소스에 대한 연결
java.net 패키지에서 제공하는 4개의 socket
Socket : TCP 클라이언트 API, 일반적으로 원격 호스트에 연결하는 데 사용됨
ServerSocket : TCP 서버 API, 일반적으로 클라이언트 소켓의 연결 허용
DatagramSocket : UDP 엔드포인트 API, datagram 패킷을 주고 받는데 사용
MulticastSocket : multicast 그룹을 처리하는 DatagramSocket의 하위클래스
TCP 소켓을 통한 송수신 -> Socket.getInputStream() 메소드 및 Socket.getOutputStream()메소드를 통해 얻을 수 있는 InputStreams 및 OutputStreams를 통해 수행됨
* Socket 관련 Timeout
Connection Timeout
Socket Timeout / Read Timeout
1. Connection Timeout
클라이언트가 서버측으로 Connection을 맺길 원하지만 서버의 장애 상황으로 맺어지지 못할 때 발생하는 timeout
이 경우에는 서버에 접근이 안되는 경우라서 클라이언트는 서버의 장애 상황으로 간주할 수 있음. 보통 이 경우에 클라이언트는 일시적인 오류 상황으로 구분하여 처리를 하거나 미리 정의된 dafault 데이터나 cache 데이터로 fallback 처리하기도 함.
Connection 과정
TCP 소켓 통신에서 클라이언트와 서버가 연결될 때 정확한 전송을 보장하기 위해 상대방 컴퓨터와 사전에 세션을 수립함. (3-way handshake)
3-way handshake가 정상적으로 끝나야 Connection이 됐다고 표현할 수 있음. 즉, Connection Timeout이란 3-way HandShake가 정상적으로 수행되어 서버에 연결되기까지 소요된 시간임.
TCP 3-way HandShake 절차
1) 클라이언트 A 는 B 서버에 접속을 요청하는 SYN 패킷을 보냄. 이때 A는 SYN을 보내고 SYN/ACK 응답을 기다리는 SYN_SENT 상태가 됨
2) B 서버는 SYN 요청을 받고 A에게 요청을 수락한다는 ACK와 SYN flag가 설정된 패킷을 발송하고 A가 다시 ACK으로 응답하길 기다린다. 이때 B 서버는 SYN_RECEIVED 상태가 됨
3) A는 B에게 ACK을 보내고 이후부터는 연결이 이뤄지고 데이터가 오가게 되는 것이다. 이때 B 서버 상태는 ESTABILSHED이다.
SYN : synchronize sequence numbers
ACK : acknowledgement
4-way handshake : 3-way handshake는 TCP의 연결을 초기화할 때 사용한다면, 4-way handshake는 세션을 종료하기 위해 수행되는 절차임
2. Socket Timeout
클라이언트와 서버가 connection을 맺은 후 서버는 데이터를 클라이언트에게 전송하게 됨. 이때 실제 데이터를 주고 받는 과정은 하나의 데이터 덩어리가 아닌 여러개의 패킷으로 나눠서 전송되는데 각 패킷이 전송될 때 시간 차(Gap)가 있음. 이 차이 시간의 제한(임계치)을 SocketTimeout이라고 함.
read timeout과의 관계
클라이언트와 서버가 connection은 맺어졌지만 I/O (Input/Out) 작업이 길어지거나 락이 걸려 요청이 처리되지 못하고 있을 때 클라이언트는 더 이상 기다리지 못하고 커넥션을 끊음. 이런 상황을 Read Timeout이라고 함.
클라이언트와 서버가 connection에는 성공했지만 실제 데이터를 전송하는 I/O 과정이 길어지는 경우 일정 시간이 경과되면 클라이언트는 connection을 끊게 됨.
보통 주고 받는 데이터의 양이나 네트워크 속도에 따라서 대응을 다르게 함. 만약 데이터의 양이 크다면 이를 분할해서 받을 수 있도록 API 자체 Spec을 변경하거나 Retry 전략을 사용할 수 있고, 속도가 느려서 발생하는 상황이라면 전반적으로 네트워크 대역폭 증가를 위한 인프라 작업을 고려할 수 있음
* Connection, Socket/Read Timeout과 관련된 예외
java.net.Socket.Exception : Thrown to indicate that there is an error creating or accessing a Socket. -> connection timeout
java.net.SocketTimeoutException : Signals that a timeout has occurred on a socket read or accept. -> socket timeout, read timeout
2) HttpClient 라이브러리
Apache HttpClient
HTTP 프로토콜을 손쉽게 사용할 수 있게 해주는 클라이언트측 HTTP 전송 라이브러리
Apache HttpComponents 제품군의 HttpClient는 http 통신을 위한 표준이 되어옴
httpURLConnection의 단점(connection pooling)을 채우는 다양한 API를 가진 성숙한 프로젝트
Apache HttpClient를 이용하면 간편하게 HTTP request를 보낼 수 있음. 간혹 웹 서버를 만들면서 다른 서버로부터 request를 보내 response받아 데이터를 처리해야할 때가 있음. 이때 HttpClient를 이용하면 간단하게 구현 가능
java.net 패키지와의 차이점
java.net 패키지는 HTTP를 통해 리소스에 액세스하기 위한 기본 기능을 제공하지만, 많은 애플리케이션에 필요한 완전한 유연성이나 기능을 제공하지 않음
HttpClient 패키지는 최신 HTTP 표준 및 권장 사항의 클라이언트 측을 구현하는 효율적이고 최신이며 기능이 풍부한 패키지를 제공해 이 공백을 채우려고 함
확장을 위해 설계된 HttpClient는 기본 HTTP 프로토콜에 대한 강력한 지원을 제공하는 동시에 웹 브라우저, 웹 서비스 클라이언트 또는 분산 통신을 위해 HTTP 프로토콜을 활용하거나 확장하는 시스템과 같은 HTTP 인식 클라이언트 응용 프로그램을 구축하는 모든 사람에게 유용할 수 있음
HttpClient에서 제공하는 timeout 관련 메소드
setConnectTimeout : 서버와 연결을 맺을 때의 타임아웃
setConnectionRequestTimeout : ConnectionManager(커넥션풀)로부터 꺼내올 때의 타임아웃
setSocketTimeout : 요청/응답간의 타임아웃
Connection Pooling
HttpClient로 빈번히 connection을 맺었다가 사용이 끝나고 끊고 하다 보면 더 이상 Connection을 열 수 없는 경우가 발생할 수 있음
connection을 닫는다고 호출을 해도 실제로는 어느정도 TIME_WAIT 상태에 있다가 끊어지는데 이런 것들이 많이 쌓여 있으면 File Descriptor가 꽉 찼다는 에러(Too Many Open Files)가 나면서 connection을 맺지 못하게 된다.
이런 현상을 방지하기 위해서 Connection을 재사용할 수 있도록 HttpClient에서 제공하는 Connection Pool을 사용함 (getHttpClient를 호출할 때 Connection Pool이 지정된 사이즈로 생성되고 Connection을 하나 만들어 리턴함)
Pool을 사용할 때마다 항상 주의해야할 것은 반환을 꼭 해 줘야한다!
Timeout 예시
# HttpClient 4.3 (Configure Timeouts Using the New 4.3 Builde)
int timeout = 5;
RequestConfig config = RequestConfig.custom()
.setConnectTimeout(timeout * 1000)
.setConnectionRequestTimeout(timeout * 1000)
.setSocketTimeout(timeout * 1000).build();
CloseableHttpClient client =
HttpClientBuilder.create().setDefaultRequestConfig(config).build();
그러면 Service Provider에서는 Resource Owner가 로그인하여 리소스 사용을 승인할 수 있는 페이지로 302 응답을 통해 Resource Owner를 이동시킨다.
이 페이지는 Client가 사용할 권한 목록을Resource Owner에게 명시적으로 보여주며, Resource Owner는 이에 동의 시 "나는 Client가 Scope에 명시한 범위 안에 있는 내 데이터에 접근할 권한을 부여하는 것에 동의합니다"라고 말하는 것과 같다.
3. Access Token 발행 요청
Client는 서비스 제공자에게 Client Id와 Secret Key, Access Token이 발행되면 아까 Authentication Code를 발급 받을때 사용했던 Redirect Url, 그리고 아까 Resource Owner에게 받은 인가 코드를 가지고 Access Token을 발행 요청을 한다.
서비스 제공자의 인증 서버는 리소스에 접근할 수 있는 Access Token과 Refresh Token을 발행하고 Client에게 보내준다.
4. 리소스에 접근 요청
Access Token을 받고 Client는 이 토큰을 통해 Resource Server에서 사용자의 정보에 접근한다.
Access Token이 저장된 DB에 비교하여 지정된 Scope에 접근하는 게 맞는지 확인 후 돌려준다.
보통 헤더에 많이 세팅한다.
5. Access Token 재발급 요청
시간이 지나서 Access Token이 만료된다면 좀 전에 말했듯이 Refresh Token을 통해 새로 발급받을 수 있다.
Access Token을 발급받을 때 보통 expires라는 항목으로 유효시간이 같이 넘어오는데, 이를 통해 유효시간이 지났는지 확인할 수 있고 지났으면 Refresh Token으로 재발급받는다.
🍀 구글 OAuth API 프로젝트 환경구성
구글 API를 사용하기 위해서는 우선 하단의 사이트에서 일련의 구성및 허가 과정을 거쳐야 한다.
Spring에서 컨트롤러를 지정해주기 위한 어노테이션은 @Controller와 @RestController가 있다.
전통적인 Spring MVC의 컨트롤러인 @Controller와 Restuful 웹서비스의 컨트롤러인 @RestController의 주요한 차이점은 HTTP Response Body가 생성되는 방식이다.
근본적인 차이는 @Controller의 역할은 Model 객체를 만들어 데이터를 담고 View를 찾는 것이지만, @RestController는 단순히 객체만을 반환하고 객체 데이터는 JSON 또는 XML 형식으로 HTTP 응답에 담아서 전송한다.
@Controller은 뷰에 표시될 데이터가 있는 Model 객체를 만들고 올바른 뷰를 선택하는 일을 담당한다.
또한, @ResponseBody를 사용하여HTTP Response Body에 데이터를 담아 요청을 완료할 수 있다.
HTTP Response Body에 데이터를 담는 것은 RESTful 웹 서비스에 대한 응답에 매우 유용한데, 뷰를 반환하는 대신 데이터를 반환하기 때문이다.
하지만 @RestController을 사용하여 동일한 기능을 제공할 수 있다.
요컨대 @Controller와 @ResponsBody의 동작을 하나로 결합한 편의 컨트롤러라 보면 된다.
다음 두 코드는 Spring MVC에서 동일한 동작을 한다.
@Controller
@ResponseBody
public class MVCController{
logic...
}
@RestController
public class ReftFulController{
logic...
}
대부분의 개발자들은 두개의 어노테이션이 아닌 하나의 어노테이션만 선언하고 싶어할 것이다.
또한, @RestController는 이전 두개보다 의미에 대해서 명확히 나타내고 있다.
@RestController vs @Controller
1. @Controller는 클래스를 Spring MVC 컨트롤러로 표시하는데 사용되며 @RestController는 RESTful 웹 서비스에서 사용되는 특수 컨트롤러이다. @Controller + @ResponseBody와 동일하다.
** RESTful 웹서비스란 : url을 통해 데이터를 요청하고 그 데이터는 XML 형식으로 반환
출처 : https://kimseunghyun76.tistory.com/18
+) REST 의 특징
1) REST 방식의 웹서비스는 잘 정의된 Cool URI로 리소스를 표현.
무분별한 파라미터의 남발이 아닌 마치 오브젝트의 멤버 변수를 따라가듯이 정의
2) REST 방식의 웹서비스는 세션을 쓰지 않는다.
기존의 서블릿 개발에서는 세션을 이용해서 인증 정보를 가지고 다니는데 요청 처리가 매우 무거워진다. 그리고 요청의 전후 관계에 관련성이 생기기에 한 세션의 일련의 요청을 하나의 서버가 처리해야 한다. 하지만 REST는 세션을 사용하지 않기에 각각의 요청이 완벽하게 독립적이다.
3) REST란 4가지 속성을 지향하는 웹서비스 디자인 표준이다.
ROA는 웹의 모든 리소스를 URI로 표현하고, 모든 리소스를 구조적이고 유기적으로 연결하여 비 상태 지향적인 방법으로 정해진 method만을 사용하는 아키텍쳐다.
* Addressablilty (주소로 표현 가능함) - 제공하는 모든 정보를 URI로 표시할 수 있어야 한다.
* Connectedness (연결됨) - 일반 웹 페이지처럼 하나의 리소스들은 서로 주변의 연관 리소스들과 연결되어 표현(Presentation)되어야 한다.
* Statelessness (상태 없음) - 현재 클라이언트의 상태를 절대로 서버에서 관리하지 않아야 한다.(REST에서는 상태가 서버가 아니라 클라이언트에 유지되며 매 요청마다 필요한 정보를 서버에 보낸다.) - 모든 요청은 일회성의 성격을 가지며 이전의 요청에 영향을 받지 말아야 한다. - 세션을 유지 하지 않기 때문에 서버 로드 밸런싱이 매우 유리하다. - URI에 현재 state를 표현할 수 있어야 한다. (권장사항)
* Homogeneous Interface (동일한 인터페이스) - HTTP에서 제공하는 기본적인 4가지의 method와 추가적인 2가지의 method를 이용해서 리소스의 모든 동작을 정의한다. - 대부분의 리소스 조작은 6가지의 method를 이용하여 대부분 처리 가능하다. 만일 이것들로만 절대로 불가능한 액션이 필요할 경우에는 POST를 이용하여 추가 액션을 정의할 수 있다. (되도록 지양하자)
REST는 웹의 모든 리소스를 URI로 표현하고 이를 구조적이고 유기적으로 연결하여 비 상태 지향적인 방법으로 일관된 method를 사용하여 리소스를 사용하는 웹 서비스 디자인 표준이다.
2. @RestController는 Spring 4.0에서 추가되었지만, @Controller는 Spring이 주석을 지원하기 시작한 이후에 존재하며 공식적으로 Spring 2.5 버전에서 추가되었다.
3. @Controller는 @Component 주석이 달려있고 @RestController는 아래와 같이 @Controller와 @ResponseBody 주석이 달린 편의 컨트롤러이다.
@Target(value=TYEP)
@Retention(value=RUNTIME)
@Documented
@Controller
@ResponseBody
public @interface RestController
@Target(value=TYEP)
@Retention(value=RUNTIME)
@Documented
@Component
public @interface Controller
4. 주요 차이점 중 하나는 @RestController을 표시하면 모든 메소드가 뷰 대신 객체로 작성된다!
일반적인 Spring MVC 처리 과정
위 사진에서 볼 수 있다싶이 @RestController를 클래스에 달면 모든 핸들러 메소드에서 @ResponseBody를 사용할 필요가 없다!
@Controller
@RequestMapping("books")
public class SimpleBookController {
@GetMapping("/{id}", produces = "application/json")
public @ResponseBody Book getBook(@PathVariable int id) {
return findBookById(id);
}
private Book findBookById(int id) {
// ...
}
}
@RestController
@RequestMapping("books-rest")
public class SimpleBookRestController {
@GetMapping("/{id}", produces = "application/json")
public Book getBook(@PathVariable int id) {
return findBookById(id);
}
private Book findBookById(int id) {
// ...
}
}
결론은 REStful 웹 서비스를 만드는 경우 @Controller + @ResponseBody를 사용하는 것보다 @RestController을 사용하는 것이 좋다!