[JPA] Jmeter로 쿼리문 성능 개선하기 (1) - 여러 조건이 포함된 조회 쿼리를 어떻게 개선시킬까?
티쳐포보스 프로젝트 개발 중 '같은 업종 사장님 평균 점수 조회' API를 맡게 되었다.
1. 시험을 치룬 유저의 내역 중 특정 기간에 해당되는 유저의 시험 점수 평균을 낸다.
2. 시험을 치룬 유저가 아닌 다른 유저들의 특정 기간에 해당되는 시험 점수 평균을 낸다.
현재 1번의 조회 쿼리문은 아래와 같다.
네이티브 쿼리를 활용하여 유저의 시험 내역 (member_exam) 중 점수값만 추려 평균값을 반환한다.
@Query(value = "select round(avg(me.score)) from member_exam me " +
"where me.member_id = :memberId " +
"and month(me.created_at) between :first and :last " +
"and me.status = 'ACTIVE'", nativeQuery = true)
Optional<Integer> getAverageByMemberId(@Param("memberId") Long memberId, @Param("first") int first, @Param("last") int last);
2번의 조회 쿼리문은 아래와 같다.
1번 쿼리문과의 차이점은 member_id가 아닌 유저의 id값들의 점수값만 추려 평균값을 반환한다.
@Query(value = "select round(avg(me.score)) from member_exam me " +
"where me.member_id <> :memberId " +
"and month(me.created_at) between :first and :last " +
"and me.status = 'ACTIVE'", nativeQuery = true)
Optional<Integer> getAverageByMemberIdNot(@Param("memberId") Long memberId, @Param("first") int first, @Param("last") int last);
쿼리를 짜면서 드는 생각이,
네이티브 쿼리로 바로 평균값을 도출해서 반환하는 게 성능상 괜찮을까?
혹은 바로 점수값을 계산하지 않고, member_exam 리스트만 반환하여 비즈니스 로직에서 평균값을 계산하는게 더 빠를까?
혹은 저 쿼리문보다 더 개선된 쿼리문으로 리팩토링할 수 없을까?
하여 Jmeter를 활용해 성능 부하를 테스트해보기로 하였다!
우선 하단 링크에 접속하여 Jmeter를 설치해주고,
https://jmeter.apache.org/download_jmeter.cgi
Apache JMeter - Download Apache JMeter
Download Apache JMeter We recommend you use a mirror to download our release builds, but you must verify the integrity of the downloaded files using signatures downloaded from our main distribution directories. Recent releases (48 hours) may not yet be ava
jmeter.apache.org

윈도우 기준 apache-jmeter-5.6.3.tgz 를 설치해준 뒤, bin 폴더의 jmeter.bat 파일을 실행해준다.

프로그램을 실행시킨 뒤, test Plan에서 add > Threads > Thread Group으로 부하를 만들 스레드 그룹을 생성해준다.

총 100명의 유저가 1초안에 반복적으로 5번 API 요청을 보내도록 조건을 수정했다!

부하를 일으킬 HTTP Request를 작성해주고 테스트해본 결과 평균 3363ms이 소요된다.
차례대로 조건과 쿼리문을 수정해가며 성능을 개선해보자!
+) SQL 프로시저를 활용하여 더미데이터 약 5천건을 생성했다.

더미데이터로 부하 테스트를 한 결과, 2288ms가 소요되었다.

0. 쿼리 실행 계획
우선 성능을 개선하고자 하는 쿼리 실행 계획을 살펴보자.



상단의 실행 계획은 사용자 평균 점수 조회 쿼리문이다.



상단의 실행 계획은 사용자 외 같은 업종 사장님들의 평균 점수 조회 쿼리문이다.
1. 객체만 조회하여 비즈니스 로직에서 점수 계산하기
이 방법을 먼저 고민한 이유는, JPQL을 통해 '점수'만, 혹은 조건에 해당하는 MemberExam 객체 리스트들만 조회하는 메서드를 생성하여 추후 재활용성을 위해 고려하였다.
우선 Repository 메서드를 아래와 같이 생성한다.
(기존에 네이티브 쿼리로 작성하였으므로, 동일하게 네이티브 쿼리로 작성한다!)
@Query(value = "select score from member_exam me " +
"where me.member_id = :memberId " +
"and month(me.created_at) between :first and :last " +
"and me.status = 'ACTIVE'", nativeQuery = true)
Optional<List<Integer>> findMemberExamsByMemberId(@Param("memberId") Long memberId, @Param("first") int first, @Param("last") int last);
@Query(value = "select score from member_exam me " +
"where me.member_id <> :memberId " +
"and month(me.created_at) between :first and :last " +
"and me.status = 'ACTIVE'", nativeQuery = true)
Optional<List<Integer>> findMemberExamsByMemberIdNot(@Param("memberId") Long memberId, @Param("first") int first, @Param("last") int last);해당 쿼리로 생성하는경우 MemberExam 객체 (score) 리스트를 반환한다.

비즈니스 로직도 다음과 같이 변경했다.

Jmeter로 성능 부하 테스트를 한 결과, 3485ms가 소요되었다.
MemberExam 객체 리스트, 혹은 MemberExam (score) 객체 리스트만 반환하는 repository 메서드를 생성하여 재사용이 가능하게끔 나중에 리팩토링하면 좋을 거 같다~ 라고 팀원들과 얘기했었는데, 테스트를 통해 결과를 확인하니 그러지 않아도 될 거 같다 ㅎㅎ..
데이터가 많이 쌓이지 않아 엄청난 차이는 나지 않았지만, 누적된 데이터에 따라 해당 쿼리를 호출한다면 크게 영향을 미칠 것이다.
해당 메서드가 필요하다면 따로 나중에 추가하기로 ..!
2. @QueryHints 추가하기
Repository 메서드에 읽기 전용 쿼리 힌트를 적용하는 것이다.
JPA는 데이터베이스 SQL 힌트 기능을 제공하지 않고, 하이버네이트가 제공한다.
그렇기에 읽기 전용 쿼리 힌트를 추가해서 사용한다면 스냅샷을 보관하지 않고 메모리상의 이점을 얻을 수 있다.
기존 메서드에 아래 힌트를 추가로 달아주었다.
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"))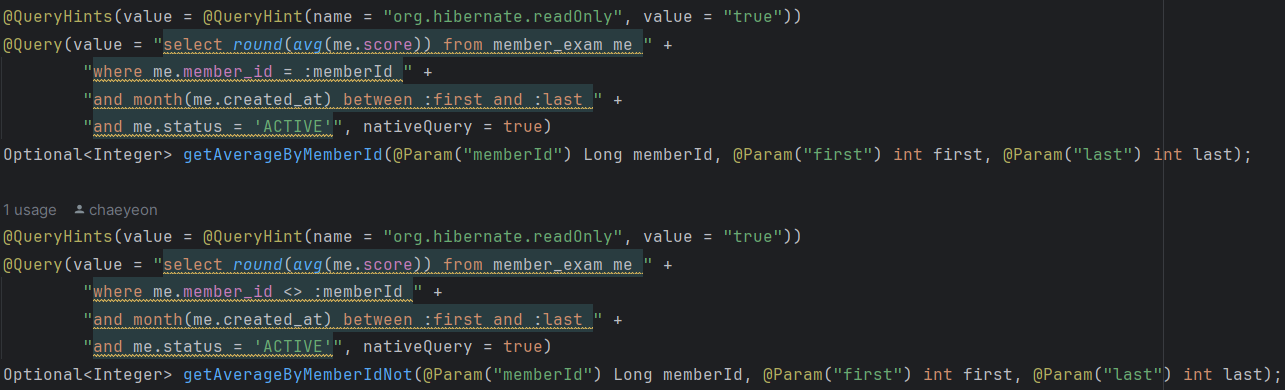
그렇게 테스트를 해본 결과..

기존 쿼리보다 200ms가 줄어들었다!
+) 더미데이터 생성 결과 2197ms로, 기존 쿼리보다 약 100ms 줄어들었다.

3. 날짜 조건 비교 Between에서 부등호 비교로
2번에 이어서 진행하면, 기존 쿼리에서 month(me.created_at) between :first and :last 조건으로 날짜별 시험 분기처리를 진행한다.
이때 Between이 아닌 부등호 비교를 하면, 부등호 조건으로 스캔 시작점이 달라지기에 스캔 범위가 줄어들 수 있다.
CPU Cycle을 적게 소모할 수 있기에, 쿼리문을 수정하고 다시 부하 테스트를 진행했다.
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"))
@Query(value = "select round(avg(me.score)) from member_exam me " +
"where me.member_id = :memberId " +
"and month(me.created_at) >= :first and month(me.created_at) <= :last " +
"and me.status = 'ACTIVE'", nativeQuery = true)
Optional<Integer> getAverageByMemberId(@Param("memberId") Long memberId, @Param("first") int first, @Param("last") int last);
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"))
@Query(value = "select round(avg(me.score)) from member_exam me " +
"where me.member_id <> :memberId " +
"and month(me.created_at) >= :first and month(me.created_at) <= :last " +
"and me.status = 'ACTIVE'", nativeQuery = true)
Optional<Integer> getAverageByMemberIdNot(@Param("memberId") Long memberId, @Param("first") int first, @Param("last") int last);

쿼리힌트를 적용한 쿼리문 호출했을 때보다 약 100ms 가량 줄어들었다!
현재 DB에 많은 양의 데이터가 들어 있지 않아 엄청난 큰 차이는 아니지만, 이는 추후 더미 데이터가 쌓일 때 유의미하게 작용할 거라 생각한다.
+) 더미데이터 생성 결과, 2005ms가 소요되었다.
기존 쿼리보다 약 200ms 가량 감소되었다!

4. NOT, != 와 같은 부정 조건 대체
3번 쿼리 중 사용자 외 같은 업종 종사하는 사장님들의 평균 점수를 조회하는 쿼리에서, where me.member_id <> :memberId 와 같이 부정연산자 <>를 쓴 걸 확인할 수 있다.
부정 연산자의 경우 해당 조건 외 나머지 인덱스에 해당하는 것을 찾는 것이기에, 지정된 대상 외 나머지라는 것 자체를 알기 위해서는 전체를 읽어야만 알 수 있다.
그렇기에 부정 조건을 대체하고 left outer join을 통해 인덱스를 추가하여, 새로 추가된 memberId 컬럼이 null인 경우만 조회하는 쿼리로 변경해보았다.
select round(avg(me.score)) from member_exam me
left outer join (select member_id from member_exam where member_id = :memberId) m on me.member_id = m.member_id
where m.member_id is null
and month(me.created_at) >= :first and month(me.created_at) <= :last
and me.status = 'ACTIVE'select 서브 쿼리를 추가했고, left outer join을 통해 m.member_id is null 인 조건만 조회하기!

성능 부하 테스트를 해본 결과, 3번에 이어 500ms 가 줄어들었다.
리팩토링 전 시간에 비하면 약 1.1초가 줄어든 결과이다.
적은 데이터이지만 확실히 속도를 단축시킬 수 있어 뿌듯하다 ㅎㅅㅎ
추후 DB에 프로시저로 더미데이터를 생성해서, 더 확실한 성능 개선 결과값을 측정해 업데이트해야겠다!
+) 더미 데이터 테스트 결과

최종 리팩토링한 쿼리 결과 14104ms가 소요되었다.
이전에 갖고 있던 데이터로 테스트했을 때는 <>보다 left outer join으로 속도를 빠르게 개선시킬 수 있을 줄 알았는데, 더미데이터 바탕으로 테스트해보니 이전보다 몇 배는 더 오래 걸렸다...!
부정 조건으로 나머지 조건들을 다 탐색해야해서 시간이 더 걸릴 줄 알았는데, 오히려 추가적인 join 과정이 불필요하게 시간을 더 늦춘 거 같다.
실제 데이터를 활용해 결과를 확인함으로써 쿼리 로직 한 줄의 소중함을 몸소 깨달을 수 있었고,
이론이 맞다고 해서 실제 탐색 결과가 항상 동일하지 않다는 걸 알 수 있었다.
쿼리를 이리 저리 수정하고 테스트해보며 더 나은 성능을 도출할 수 있도록 노력해야겠다 ~!